47 мин. чтения
Примеры Резюме Junior Data Engineer 2026: Как выделиться и получить приглашение на собеседование без опыта
Знакомо чувство, когда составляешь первое резюме, но вдруг обнаруживаешь, что даже на позицию junior уже хотят 1–2 года опыта, а от стажёра ожидают работы с реальными продакшн-системами. Некоторые работодатели и вовсе требуют от позавчерашнего выпускника знаний и навыков на уровне миддла. В такой ситуации возникает ощущение тупика: без опыта не берут на работу, но где взять опыт без работы. И это распространенная практика в различных отраслях, дата инженерия здесь не исключение.
Не нужно опускать руки. Даже сразу после получения диплома по компьютерным наукам и дата-инженерии есть высокие шансы устроиться в хорошую компанию, даже топ-уровня. Для этого необязательно быть вундеркиндом с энтерпрайз-проектами за плечами. Необходимо резюме, которое подчеркнет то, что уже есть, и выделит сильные стороны, например:
- опыт запуска реальных пайплайнов с реальными результатами;
- умение быстро обучаться, вникать в тонкости;
- реальную пользу, которую даже без опыта вы можете принести новой команде.
Я - сертифицированный карьерный коуч (CPCC) и за годы работы помог сотням инженеров устроиться в компании из разных компаний. Я знаю, как составить резюме инженера по данным без опыта, которое привлечен внимание HR-менеджера и принесет собеседование в хорошей компании можно, и это не так сложно кажется. Один из критериев — понимать, что именно ищут рекрутеры и менеджеры по кадрам.
Я говорю не абстрактно, я делюсь не только знаниями, полученными на курсах по карьерном развитию, но и собственным опытом. Я тоже когда-то начинал путь от джуниора, дорос до сеньор-инженера и даже лично участвовал в подборе кадров. Я побывал по обе стороны и знаю, как должно быть резюме младшего дата-инженера, чтобы вам точно позвонили.
В этом гайде:
✅ Как адаптировать резюме под конкретную вакансию, как показать, что у вас есть нужные навыки без реального опыта;
✅ На что рекрутеры и HR-менеджеры действительно смотрят в резюме дата-инженера джуна, а еще типичные ошибки, которые могут нивелировать даже сильный бэкграунд;
✅ Как структурировать каждый раздел резюме джуну: от шапки и summary до проектов, стажировок и сертификатов;
✅ Как интегрировать ключевые слова и метрики, чтобы твое резюме не отфильтровалось в ATS;
✅ Как практические занятия и курсовые проекты правильно представить в резюме, чтобы показать навыки работы с технологиями без реального опыта работы;
✅ Примеры резюме младшего инженера по данным, которые составлены на основе советов из этого руководства.
Этот гайд будет полезным как выпускникам, так и кодерам и аналитикам, решившим сменить профиль и перейти в инженерию данных. Только рабочие советы и инсайты HR-менеджеров, которые актуальны в 2026 году.
Хочешь сэкономить время и не возиться с резюме вручную? Попробуй наш Конструктор резюме
Не хочется тратить часы на форматирование и заполнение шаблонов в Google Docs и Word без какой-либо гарантии, что усилия окупятся? Это и необязательно. Оставьте дизайн и структуру технологиям, сосредоточьтесь на своих результатах. Конструктор резюме на engineernow.org создан с учетом ожиданий, которые рекрутеры выдвигают для инженеровs.
В конструктор резюме EngineerNow:
✔ Готовые шаблоны резюме, оптимизированы под ATS и адаптированы под уровень опыта. Все ключевые блоки — технические навыки, проекты, опыт, образование — со стандартными названиями и на своих местах. Простая настройка стилей.
✔ Помощь с формулировками. Подсказки по глаголам действия, готовые формулировки для пунктов опыта, названия сертификатов и ассоциаций собраны из сотен успешных резюме data-инженеров. Остается добавить в один клик и подставить свои результаты.
✔ Быстрая кастомизация под вакансию. Легко адаптировать резюме под позицию в несколько кликов: замена заголовка, акценты в навыках, AI-помощник для Summary, импорт из файла и др.
✔ Экспорт и скачивание. Скачивание в формате PDF или MS Word (.docx). Документ с оптимальными интервалами и полями. Документ легко читать, 100% точность извлечения информации парсером.
Это самый быстрый путь от чистого листа до резюме, готового к собеседованию.
Как создать резюме? Зарегистрируйся на engineernow.org
Пример резюме №1: Junior Data Engineer
Алексей Кузнецов
Младший инженер по данным (Junior Data Engineer)
Санкт-Петербург, Россия
Email: alex.kuznetsov@email.com | LinkedIn: linkedin.com/in/alex-kuznetsov-de | GitHub: github.com/alex-k-dev
Цель
Мотивированный Junior Data Engineer с прочной базой в построении и оптимизации дата-пайплайнов. Практический опыт через учебные проекты и стажировки с использованием Python, SQL и облачных сервисов. Стремлюсь применять технические навыки и умение решать задачи для поддержки data-driven решений и достижения целей компании.
Ключевые навыки и подтверждающие проекты
● Разработка Дата-Паплайнов:
○ Построил автоматизированный ETL-пайплайн на Python и Apache Airflow для университетского проекта, обрабатывающий данные из нескольких API-источников и сокративший время ручного сбора данных на 10 часов в неделю.
● Облачные Data Warehouse:
○ Спроектировал и внедрил облачное хранилище данных на Amazon Redshift, организовав сырые данные в звездообразную схему, что улучшило производительность аналитических запросов на 40%.
● Потоковая обработка данных:
○ Разработал прототип системы обработки данных в реальном времени с использованием Kafka и Spark Structured Streaming для анализа ленты социальных сетей, обрабатывая около 50 000 сообщений в день.
Опыт работы
Стажер, Data Engineering | Netflix | Лос-Гатос, Калифорния, США (удаленно)
Май 2024 — Август 2024
- Поддерживал команду контент-аналитики, помогая с задачами валидации данных и поддержкой существующих DAG в Airflow.
- Приобрел практический опыт работы с Python, SQL и Apache Spark в производственной среде, продемонстрировав способность работать с корпоративными системами.
- Активно участвовал в командных ревью и вносил вклад в улучшение процессов.
Образование
Бакалавр Data Science | Балтийский государственный технический университет (БГТУ)
Релевантные курсы: Структуры данных и алгоритмы, Системы баз данных, Облачные вычисления, Распределенные системы
Языки
Русский язык (родной), Английский язык (продвинутый)
Почему это резюме работает:
Этот пример резюме младшего дата-инженера эффективно доносит до читателя (работодателя) потенциал: умение быстро вникнуть в новые инструменты, знание всего стека, а не отдельных технологий. Резюме в функциональном формате — выделены проекты, которые доказывают знание на практике инструментов и технологий (работа с пайплайнами, интеграция с облаком). Что важно, количественная оценка результатов («10 часов в неделю», «улучшение на 40%») доказывает, что соискатель не просто знаком с интерфейсом, но может с помощью указанных технологий решать конкретные задачи.
В резюме дата инженера стандартное форматирование и структура. Его легко читать, парсер правильно считает информацию и отфильтрует в соответствии с настройками рекрутера. Успешно превращает академический опыт в профессиональные достижения.
Как выделиться джуну (даже если кажется, что не дотягиваешь)
Вот что сводит с ума выпускника, которые претендуют на должность инженера данных: открываешь вакансию с пометкой «entry-level» или «junior», скроллишь вниз — и натыкаешься на требования типа «3+ года с Airflow», «опыт работы со Spark в продакшене», «экспертиза в Kubernetes». И так раз за разом, десятки вакансий, как в топовых корпорациях, так и мелких стартапах, все одно и тоже. Легко может закрасться мысль, что нормальную работу не найти.
СТОП
Расскажу одну мысль, сейчас, с опытом более 15 лет она кажется очевидной. Но в начале карьеры… Жаль, что к ней я пришел не сразу: компании не ищут полностью готового инженера, когда публикуют вакансию стажера. Но как же тогда с описанием требований? Это скорее лист пожеланий, даже в топ компаниях много “романтиков”, которые хотели бы на ставку джуна найти ведущего инженера по данным. Список требований — это максимальные требования, чтобы отсеять тех, кто совсем ничего не умеет. Но в реальности нужен тот, кто быстро учится, может отладить простой код без постоянного контроля и постоянных переделок за ним, а перспективе вольется в команду через пару месяцев.
В компании на должность джуна нужен человек с базовыми знаниями и навыками, но умением быстро учиться и, это важно, ответственно выполнять порученную часть работы, даже если это относительно простые рутинные таски.
Задача твоего резюме — не доказать, что ты уже идеальный кандидат. А показать, что ты близок к этому — и дорастешь до нужного уровня быстрее остальных. Но чтобы подчеркнуть это в резюме, важно понимать, на что обращают внимание работодатели и что важно для них.
Если короче, HRы и техлиды хотят увидеть в резюме дата-инженера джуна:
✔ умение решать типичные проблемы с помощью стека, необязательно в энтерпрайз-масштабе, но понимание логики конвейеров данных, выгрузки данных по API, работы с облачными сервисами;
✔ способность создавать эффективные data-решения, пусть и в меньшем масштабе, но которые выполняют свою задачу: упорядочивают данные, работают без сбоев и с минимальной задержкой;
✔ умение работать в команде и подстраиваться под коллектив, стек, способность быстро обучаться и в принципе понимание, почему в конкретной ситуации выбран тот или иной стек инструментов, навыки ведения технической документации.
Вот как добиться этого младшему инженеру по данным:
Покажи, что ты реально что-то делаешь руками (а не только знаешь теорию)
Любой может указать Python и SQL в списке hard skills. Но привлекает внимание не сам список, а доказательство, что ты реально умеешь использовать их в реальных условиях, даже если это не сложные задачи. Запускал ли ты pet-проект на GitHub? Участвовал в хакатоне? Контрибьютил в open-source репозиторий просто из интереса? Это ценнее всего для начинающего дата-инженера. Такой опыт демонстрирует креативность, лидерские качества и активную вовлеченность в технологии инженерии данных.
Раздел «Личные проекты» — это сильный ход. Он говорит рекрутерам, что ты не просто заучиваешь синтаксис — ты строишь что-то из любопытства и мотивации. Такой подход показывает твою проактивность и искренний интерес к области.
Заполненный раздел «Личные проекты» привлекает внимание намного больше любого общего списка навыков.
Лайфхак: Если у тебя еще нет пет-проектов — начни в эти выходные. Подними простой ETL pipeline, который тянет данные из публичного API, трансформирует и загружает в Postgres. Задокументируй на GitHub с четким README. Теперь у тебя есть тема для разговора на собеседовании, чего нет у 80% соискателей. Это то, что прокачивает ваше резюме и увеличивает шансы попасть на собеседование.
Что говорят рекрутеры:
«Я беру junior-инженеров, которые могут показать, что они построили, и объяснить, почему приняли именно такие технические решения. Масштаб вторичен — важнее логика и подход».
— Михаил К.
Привязывай инструменты к конкретным действиям и таскам
Фраза «знаю Spark» для HR ничего не говорит. Важно показать как именно ты использовал Spark для решения задачи. Как это сделать?
В разделах Projects и Experience всегда связывай инструменты, с которыми работал, с конкретным результатом. Упоминай конкретные фреймворки и их влияние на эффективность обработки данных или надежность системы. Для entry-level кандидатов это критично. Работодателям важно увидеть не список технологий, а то, что ты умеешь применять их на практике: автоматизировать процессы, ускорять пайплайны, делать систему стабильнее.
Пример сильного пункта для резюме junior дата-инженера:
«Оптимизировал SQL-запросы в Redshift, сократив время загрузки дашборда с 45 до 10 сек»
Что говорят рекрутеры:
«Когда я вижу в резюме джуниора пункт “Работал с Kafka”, я сразу спрашиваю: “И что?” А когда вижу “Написал консьюмер на Java для Kafka, чтобы агрегировать метрики с 5 сервисов”, — это уже история. Я понимаю с каким стеком человек соприкасался и как он мыслит».
— Tech Lead одной из российских EdTech-компаний
Добавляй цифры: преврати учебные проекты в реальный опыт
У тебя может не быть многолетнего опыта оптимизации крупномасштабных дата-пайплайнов в корпоративной среде, но ты точно решал реальные проблемы. Разница между «курсовым проектом» и «профессиональным опытом» в резюме чаще всего не в самом проекте, а в том, как ты его описываешь. Ключевой момент — в количественной оценке влияния, даже в учебных условиях.
Подход простой: ты подаёшь свои образовательные проекты как инженерную работу. Используй метрики — скорость обработки, объём данных, снижение количества ошибок, экономию времени. Это помогает рекрутеру понять глубину знания стека.
Вместо:
❌ «Работал над курсовым проектом по анализу данных»
Попробуй:
✅ «Разработал Python ETL pipeline для извлечения и трансформации датасета в 10 ГБ, сократив время обработки данных на 30% и повысив точность аналитики для отчета нашей команды»
Что изменилось? Проект тот же. Но вторая версия:
✔ Использует отраслевую терминологию (ETL, аналитика в реальном времени)
✔ Показывает масштаб (10 ГБ данных)
✔ Показывает измеримое улучшение (−30% по времени)
✔ фокусируется на результате, а не на процессе
Даже если твоя «команда» — это ты и ещё два одногруппника, а «дашборд» — ноутбук с Matplotlib или Plotly, это всё равно реальная работа. Ты оптимизировал запросы. Ты работал с «грязными» данными. Это и есть data engineering. Именно это и должно быть в резюме.
Универсальный шаблон для пунктов в резюме дата-инженера:
[Глагол действия] + [конкретный инструмент] + [масштаб/сложность данных] + [измеримый результат]
Старайся следовать этому шаблону при составлении пунктов опыта, описании проектов. Сильные глаголы типа «Разработал», «Оптимизировал» или «Внедрил» привлекают внимание и вместе с цифрами показывают, что ты не просто работал, но добился результатов.
Что говорят рекрутеры:
«Менеджеры по найму не покупают твое прошлое — они покупают твой потенциал решать будущие проблемы. Твои прошлые успехи, даже небольшие, — лучшее доказательство этого потенциала»
— Эдвард Л.
Хорошо, теперь ты знаешь, как правильно подать свою историю в резюме.
Дальше разберем, как структурировать всё это, чтобы твое резюме доходило и до рекрутеров, и до ATS.
Образец резюме инженера по обработке данных #2: Junior Data Engineer (Аналитика и Cloud)
Александр Миллер
Младший инженер по обработке данных
Санкт-Петербург | Email: maya.thompson@example.com | LinkedIn: linkedin.com/in/mayathompson | GitHub: github.com/mayadev
О себе
Ориентированный на детали Junior Data Engineer с сильным академическим бэкграундом в компьютерных науках и практическим опытом построения, поддержки и улучшения data пайплайнов в облачных средах. Владею Python, SQL, ETL, навыки моделирования данных, сопосбность создать эффективные решения со стабильной работой. Сильный интерес к стриминговым real-time системам, машинному обучению (ML workflows) и облачным технологиям.
Технические навыки
- Языки программирования: Python, SQL, Scala
- Инструменты: Airflow, Spark, Kafka, NiFi, dbt
- Системы управления базами данных: PostgreSQL, MySQL, Snowflake, MongoDB
- Cloud: Azure, AWS (S3, Lambda, EMR), GCP BigQuery
- Прочее: APIs, Tableau, Git, основы CI/CD, data warehousing, моделирование данных, системы мониторинга, контроль качества данных
Опыт
Data Engineering Intern — Netflix (Content Analytics Team)
Апрель–Июль 2024
- Разработал автоматизированные ETL pipelines с использованием Python и Airflow, поддерживая ежедневный инжест данных из различных источников
- Построил дашборды в Tableau для аналитиков, улучшив скорость отчетности и сократив ручную работу;
- Проанализировал большие датасеты, выявив проблемы с качеством данных и улучшив точность на 27%, обеспечив надежные данные для принятия решений
- Сотрудничал с инженерами, аналитиками и дата-сайентистами для обеспечения надежной доставки данных для ML-моделей, демонстрируя коммуникативные навыки и способность работать в команде с разными департаментами
Проекты
Cloud Data Warehouse Project
Спроектировал и реализовал мини data warehouse на Redshift, организовав raw data в оптимизированные таблицы с применением best practices data modeling. Выполнил этапы обработки и трансформации, улучшив производительность запросов на 30%. Проект демонстрирует способность управлять data storage решениями в масштабе.
ML Feature Engineering Pipeline (Академический)
Построил pipeline с использованием Spark для генерации предиктивных фичей для ML use cases. Интегрировал data sources, автоматизировал этапы валидации и улучшил время обработки на 18%. Опыт представляет практические знания data workflows, поддерживающих ML-приложения.
Образование
Бакалавр Computer Science | Московский государственный технологический университет (МГТУ)
Релевантные курсы: Data Science, Big Data Systems, Machine Learning, Databases, Cloud Architecture, Statistics
Сертификаты
- Google Cloud Digital Leader
- Microsoft Azure Fundamentals
- IBM Data Engineering Certificate
Дополнительная информация
- Сильные коммуникативные навыки и умение решать проблемы
- Опыт работы в кросс-функциональных командах
- Знаком с ATS-форматированием и best practices составления резюме
- Стремление к постоянному обучению и современным data-архитектурам

Конструктор резюме
Используйте проверенные шаблоны, чтобы создать резюме, привлекающее работодателей, за считанные минуты.
СОЗДАТЬ РЕЗЮМЕАктуальная структура и формат резюме дата-инженера джуниора в 2026 году
Для инженера важны не яркий дизайн или длинные списки технологий в резюме. Важнее лаконичность, стандартная структура и шаблонные заголовки, которые ожидают увидеть рекрутеры. ATS-софт также “ждет” стандартного форматирования.
Но что именно ожидают рекрутеры и как настроены ATS-системы?
Лучший формат резюме для джуниора инженера по данным в 2026-м
Что лучше: функциональное или хронологическое резюме? Как сертифицированный профессиональный составитель резюме (CPRW), я знаю, что работает прямо сейчас. Если ты джун и только входишь в дату инженерию —
Используй гибридный формат.
Он объединяет два формата. В основе популярная структура, где подается карьерная история в обратном хронологическом порядке. Но раздел навыков подается не в виде короткого списка, а в расширенном варианте, с упоминанием знаковых проектов и задач возле ключевых технологий и инструментов.
Вот структура резюме в гибридном формате для младшего инженера по данным:
● Шапка (имя, контакты, LinkedIn, GitHub)
● Профессиональное Summary (3-4 емких строки)
● Технические навыки (сгруппированные по категориям)
● Проекты (для джуна главный раздел)
● Опыт работы / Стажировки
● Образование
● Сертификаты (если актуально)
● Другие разделы: знание иностранных языков, публикации, конференции.
Почему гибридный формат лучше
Функциональное резюме (развернутое описание навыков, а раздел с опытом отсутствует или подан коротко, упоминанием компании и датами) сразу сообщает «У меня нет реального опыта». Но даже от студента последнего курса ожидается, как минимум стажировка, а как максимум — летняя подработка и open-sourse проекты. Опусти раздел с опытом, и другие кандидаты будут впереди.
Резюме в хронологическом формате работает, только если уже есть одна — две солидные стажировки. Без них остается много пустого пространства, в резюме нет результатов и подтверждения опыта работы с конкретными инструментами.
Гибридная версия резюме берет только сильное с хронологического и функционального форматов, но лишена их недостатков:
☑️ На первое место выводит проекты, акцентирует внимание на том, что ты уже умеешь, подтверждает знание инструментов прямо в разделе с профессиональными навыками;
☑️ Сохраняет стандартную структуру, выглядит привычно для HR-менеджеров и ATS;
☑️ Не акцентирует внимание на отсутствии опыта. Сохраняет стандартный формат раздела с опытом, даже если карьерная история сводится к паре стажировок.
Когда переходить на чисто reverse-chronological формат резюме:
Только если в активе минимум две стажировки, общий опыт минимум 3-4 месяца и ты самостоятельно выполнял реальные задачи, пусть даже они были небольшими.
Итог: Для рекрутера главное не формат, а возможность за 5-10 секунд найти доказательства, что ты работал с технологиями дата-инженерии, писал реальный код и получил измеримые результаты. Используй стандартную структуру и лаконичный дизайн, чтобы добиться этого.
Структура резюме для Junior Data Engineers с кратким разбором каждого раздела
Вот структура для резюме младшего дата-инженера, которую ожидают рекрутеры и ATS. А также небольшой гайд с коротким разбором, что указать в каждом разделе.
1. Контактная информация
Шапка с контактами в самом верху — не стоит разбивать ее на насколько блоков. Должна быть безупречной: простой лаконичный дизайн, стандартные шрифты (Arial, Time New Roman…), без иллюстраций и логотипов.
Должна содержать такие данные:
● Полное имя (ФИО) - выделите увеличенным полужирным шрифтом (16-18 pt);
● Специальность и, если это актуально, специализация;
● Контакты: Номер телефона, электронная почта, ссылки LinkedIn и GitHub
● Город (опционально).
Другая дополнительная информация не нужна, например дата рождения, точный адрес, фото (если это не вакансия в ЕС), семейное положение, есть ли водительские права. И не нужно писать фразу «Рекомендации по запросу» (очевидно, что работодатель может запросить это, если нужно).
Критично: Убедись, что GitHub открыт для публичного доступа и там есть реальные проекты. Если нет — лучше просто не указывать, чем дать пустую ссылку.
Важно: используйте профессиональный адрес email (имя_фамилия@mail.com). Креативные никнеймы допустимы для креативной индустрии, но не для инженера.
2. Обзор карьеры (Summary)
Вступительный абзац, 3-4 предложения с описанием достижений, сильных сторон, целей.
Формула для сильного саммари (необязательно следовать точно, можно разбить на предложения, переставить местами):
[Твоя должность] + [ключевой навык/опыт] + [конкретный результат/проект] + [цель/ потенциальная ценность]
Слабый пример саммари для резюме дата-инженера (не привлекает внимание):
«Увлеченный дата-инженерией выпускник ИТМО, желающий расти...»
Хороший пример (мотивирует кадровика читать дальше):
«Junior Data Engineer с навыками построения масштабируемых ETL pipelines на Python и Airflow. Построил Airflow + Spark pipelines, сократившие задержку на 40% и обработавшие 200 тысяч событий в день. Готов применить cloud и data modeling навыки для повышения надежности данных и вклада в успех организации»
Правило: Адаптируй summary под компанию (стек, метрики) и требования работодателя. Это покажет, что ты выполнил “домашнюю работу” и узнал больше о компании, заинтересован в должности, ответственно подходишь к каждому делу.
3. Технические навыки
Этот раздел в резюме младшего инженера по данным выполняет несколько функций:
- это место, куда можно вставить ключевые слова для ATS: инструменты, технологии дата инженерии, другие навыки;
- здесь перечисляются основные навыки, чтобы рекрутер мог быстро оценить бэкграунд;
- доказательство главных 3-4 технических навыков — одна строка с указанием задачи и результата.
Группируй инструменты и технологии в четкие, логичные категории. Для джуниора достаточно 7-10 инструментов (максимум 15, если с каждым есть реальный опыт, пусть и в рамках академических проектов и занятий).
Пример раздела навыков для резюме дата-инженера:
● Языки программирования: Python, SQL, Java
● Big Data: Spark, Kafka, Hadoop, BigQuery
● Cloud-платформы: AWS (S3, Redshift, Lambda), GCP, Azure
● Базы данных: PostgreSQL, MySQL, MongoDB
● Другие инструменты дата-инжиниринга: Airflow, dbt, Git, Docker
Личные качества можно указать строкой или выделить в отдельный раздел с мягкими навыками.
При описании навыков превыше всего честность: Не пиши «продвинутый уровень Kafka» (Advanced Kafka), если ты только прошел локальный туториал. «Знаком с» или «Опыт использования» лучше всего подойдет для описания навыков в резюме junior дата-инженера.
4. Проекты
Этот раздел в резюме джуниора сопоставим по “ценности” с «Опытом» — на него в первую очередь обращают специалисты по кадрам. Здесь ты доказываешь, что умеешь работать с технологиями на практике. Три — четыре сильных проекта лучше, чем десять слабых.
Структура для описания каждого проекта:
● Название проекта, тип (например, «Парсинг и анализ рыночных данных»);
● Какие инструменты использовал (Python, PostgreSQL, Apache Airflow);
● Твоя роль, что сделал, какую проблему решил («Разработал скрипт для сбора данных с API»);
● Результаты с цифрами (например, «Автоматизировал процесс, сократив время еженедельного отчёта с 6 часов до 30 минут»).
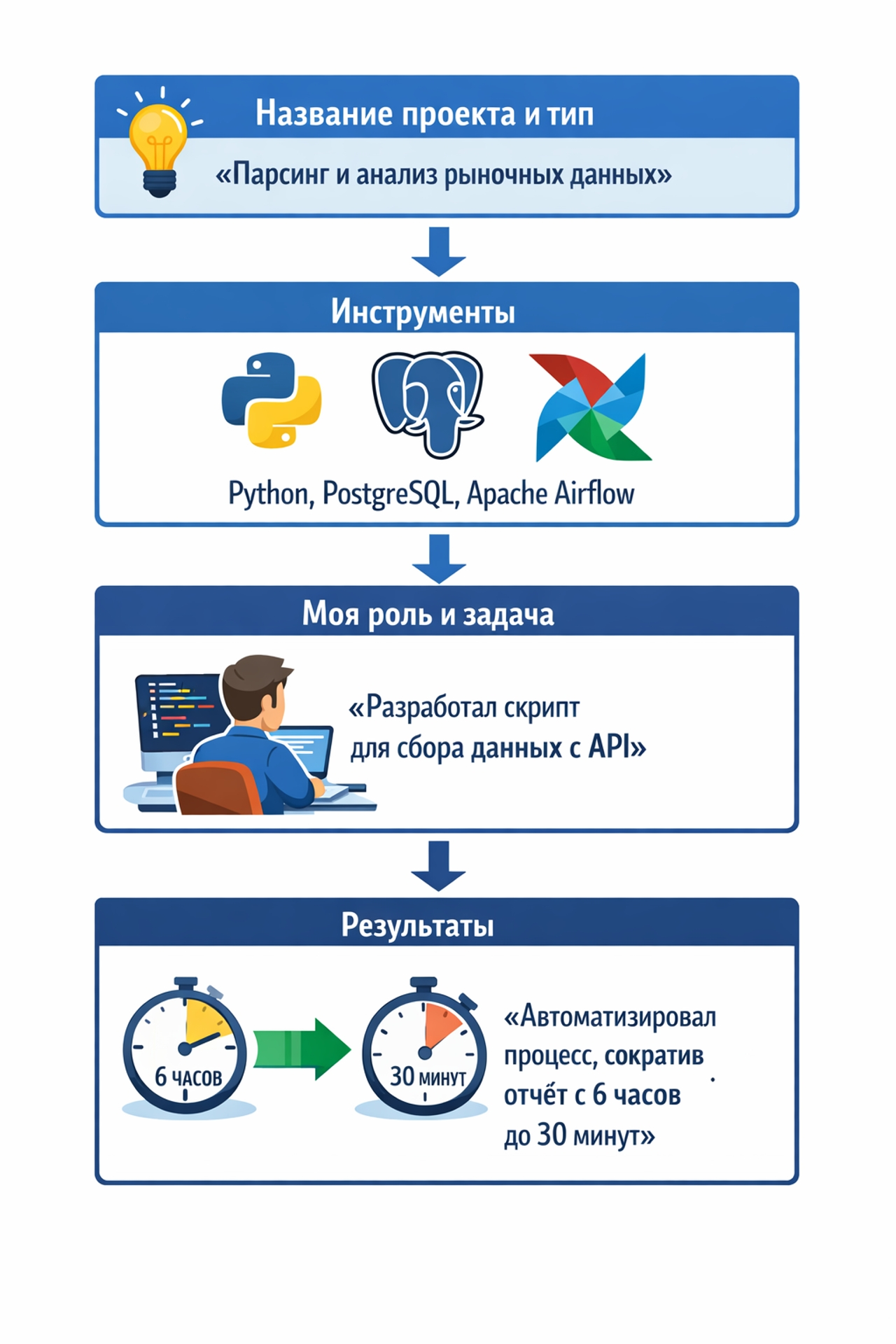
Пример:
Real-Time Clickstream Pipeline — Личный проект, 2.4k звезд на GitHub
● Собрал пайплайн, который обрабатывает около 150 тысяч событий в минуту из Kafka, настроил упорядочивание данных через Spark Structured Streaming и хранение в Delta Lake
● В рамках проекта смог сократить изначальную задержку с 90 сек до около 4 сек (96% улучшение)
● Проект развернул на AWS EMR + S3
5. Опыт работы
Даже стажировки важны для junior-кандидатов.
Структура описания каждой роли:
● Должность | Название компании | период работы
● 2-5 пунктов с описанием обязанностей, проектов, результатов. Чтобы написать цепляющие пункты, используй фреймворк: Сильный глагол + инструмент + результат
Фокусируйся на системах, с которыми соприкасался, масштабе проектов и (если актуально) на том, как твоя работа повлияла на достижение целей проекта, отдела, компании.
Пример для резюме младшего дата-инженера:
Интерн инженер по обработке данных
● Автоматизировал процесс формирования еженедельных отчетов по продажам, используя скрипты Python и SQL, сэкономил более 5 часов ручной работы в неделю для дата-аналитиков.
Совет: Если у тебя вообще нет опыта — пропусти этот раздел. Не надо писать о летних подработках, не связанных с работой с данными.
6. Образование
Для джуна раздел с описанием профильного образования по важности не уступает проектам. Недостаточно указать степень и учебное заведение, необходимо уделить образованию больше внимания. Укажи:
- степень и специальность;
- учебное заведение и год получения диплома;
- связанные с должностью курсы (базы данных, облачные вычисления, программирования);
- связанные курсовые работы, выпускную работу, академические проекты по инженерии данных;
- укажи средний балл (GPA) если он более 4,0 (для США >3.3).
Такую информацию, как форма обучения, указывать не нужно.
7. Сертификаты и непрерывное обучение
Дополнительное образование и курсы повышения квалификации показывают инициативу, профессиональное развитие и владение современным стеком. Достаточно указать названия сертификаты и год выдачи.
Пример:
● AWS Certified Data Engineer — Associate (2025).
● Google Professional Data Engineer (в процессе — ожидается январь 2026).
● dbt Analytics Engineering Certification (2025).
8. Другие разделы (Опционально, если актуально лично для тебя)
Включай дополнительные разделы только если они добавляют реальную ценность.
Что можно включить (с примером):
● Награды, участие в хакатонах: "1-е место, University Data Innovation Challenge 2025"
● Опубликованные статьи по инженерии данных: добавь ссылки на статьи в блоге или печатных изданиях (например, в университетской газете, журнале).
Дальше расскажу о том, как изложить свой бэкграунд, чтобы привлечь внимание работодателя и выделиться среди других кандидатов.
Пример резюме #3: Junior Data Engineer (ML & Streaming)
Егор Иванов
Младшний дата-инженер
Москва, Россия
Email: egor.ivanov@example.com | LinkedIn: linkedin.com/in/egor-ivanov-de | GitHub: github.com/egor-ivanov-dev
Обзор карьеры
Младший инженер по данным опытом проектирования и оптимизации ETL-пайплайнов, а также поддержки обработки данных в реальном времени для команд анализа и машинного обучения. В рамках open-sourse проекта на GitHUB взял ответственность за полный цикл разработки — от сбора требований до внедрения. Имею прочную базу в Python, SQL и облачных технологиях (AWS, GCP), практический опыт построения streaming-решений на Kafka и Spark.
Умею быстро осваивать новые технологии и готов превращать данные в действенные бизнес-инсайты. Стремлюсь развиваться в области надежных и масштабируемых data-решений.
Ключевые навыки
● Языки программирования: Python, SQL, Java
● Big Data / Обработка: Apache Spark, Apache Kafka, Hadoop
● Базы данных: PostgreSQL, MySQL, MongoDB
● Облачные платформы: AWS (S3, Lambda, Redshift), Google Cloud Platform (BigQuery)
● Инструменты ETL и оркестрации: Apache Airflow, dbt, Apache NiFi
● Прочее: Работа с API, Git, Tableau, основы машинного обучения, проектирование хранилищ данных (data warehousing), data modeling.
● Профессиональные качества: Внимание к деталям, ответственность за срок выполнения задач, уверенный пользователь современного программного стека, навыки подготовки технической документации.
Проекты
Пайплайн потоковой обработки данных в реальном времени (Дипломный проект)
Март 2024 – Июнь 2024
● Спроектировал и выполнил разработку отказоустойчивого пайплайна на Apache Kafka и Spark Streaming для обработки потока событий из социальных сетей (~150 тыс. событий/день).
● Позволило снизить задержку (latency) обработки на 35% за счет оптимизации логики обработки и настройки запросов.
● Реализовал модули для проверки качества и целостности данных, что сократило количество ошибок на этапе анализа.
Облачная ETL-система (Стажировка в VK / Аналитика рекламных данных)
Сентябрь 2023 – Декабрь 2023
● Построил автоматизированные workflows обработки данных с помощью Apache Airflow в облаке AWS, что обеспечило надежность и своевременность выполнения ежедневных отчетов.
● Настроил процесс высококачественного приема (ingestion) данных и проверки их на соответствие бизнес-правилам.
● Оптимизировал Python-скрипты, сократив среднее время выполнения задания на 22% и повысив стабильность работы с различными источниками.
Опыт работы
Стажер, Data Engineering | Ozon (Команда Data Platform) | Москва
Июнь 2024 – Август 2024
● Участвовал в проектировании и поддержке масштабируемых пайплайнов данных, что обеспечивало аналитиков актуальной информацией для принятия решений.
● Помогал оптимизировать процессы загрузки данных, сократив время простоя (downtime) ключевых пайплайнов на 18%.
● Внедрил новые DAG в Airflow и доработал существующие скрипты, улучшив их производительность и сопровождаемость.
● Активно сотрудничал с кросс-функциональными командами (аналитики, разработчики), участвуя в обсуждении требований и подготовке решений.
Образование
Бакалавр компьютерных наук
Факультет компьютерных наук, Национальный исследовательский университет «Высшая школа экономики» (НИУ ВШЭ), Москва | 2024
● Релевантные курсы: Структуры данных и алгоритмы, Базы данных, Машинное обучение, Распределенные системы, Облачные вычисления.
● Дипломный проект, защищенный на «отлично», был посвящен теме реального времени обработки больших данных.
Сертификаты и обучение
● Microsoft Certified: Azure Data Engineer Associate (2024)
● AWS Cloud Practitioner (2023)
● Профессиональный сертификат «Анализ данных» от Google (Coursera, 2023)
● Курс «Промышленный Data Engineering» (Stepik, 2023)
Дополнительно
● Желаемая должность: Junior / начинающий Data Engineer. Готов к трудоустройству на полный график.
● Уверенный пользователь программ для визуализации (Tableau, Superset) и офисного пакета.
● Внимательно отношусь к политике информационной безопасности и конфиденциальности данных.
● В свободное время изучаю архитектурные подходы к построению отказоустойчивых систем, читаю отзывы и подробнее знакомлюсь с опытом крупных компаний в сфере data.
● Готов к оформлению в соответствии с требованиями работодателя (полный пакет документов, трудовая книжка).
Как написать резюме Junior Data Engineer: советы от рекрутеров
К этому моменту ты уже понял главное: резюме младшего инженера по данным — это не просто каталог инструментов, с которыми ты хоть раз контактировал. Оно должно показывать, что ты можешь сам запускать пайплайны, которые не нуждаются в постоянном перезапуске, и готов быстро вникнуть в процессы без постоянного контроля.
Преимущество джуна — работодатель не ожидает от тебя наличия многолетнего энтерпрайз опыта. И не нужно объяснять работу над проектами, запущенными на устаревших системах, пытаясь их проецировать на современные задачи. Резюме может быть лаконичным простым. Достаточно показать, что ты можешь решать реальные задачи по обработке данных через учебные или личные проекты и примеры со стажировок.
Сильное резюме junior дата-инженера должно показывать, что ты освоил основы дата инженерии при этом способен быстро расти.
Менеджеры по найму при просмотре резюме младшего инженера всегда задают один вопрос:
Сможет ли этот человек уже в первые недели стабильно двигать данные и быстро прокачиваться?
Каждый раздел в твоем резюме должен отвечать «да».
Дальше покажу, как составить основные разделы, чтобы доказать, что ты можешь давать результат.
Как составить сильный раздел с техническими навыками
Кажется, здесь все просто: лаконичный список инструментов, ничего больше. Но даже здесь можно сделать ошибку.
Для дата-инженера джуниора раздел «Технические навыки» - это не просто список инструментов, с которыми вы знакомы. Он должен показывать, что ты освоил стек инструментов, достаточный, чтоб решать конкретные задачи по обработке данных.
Вот только два подхода, которые все еще работают для джунов:
Вариант 1: Гибридный формат резюме (Лучше для <1 года реального опыта)
Когда опыт ограничен или отсутствует, самый лучший способ — превратить раздел с техническими навыками в небольшую выжимку из проектов. Сгруппируй скиллы в 4-5 категорий, возле каждой группы приведи доказательством — буквально одно предложение с описанием задачи, используемых инструментов и результатами.
Пример раздела с навыками для гибридного резюме entry-level дата-инженера:
☑️ Data Pipeline Development: Airflow, dbt
Построил end-to-end Airflow + dbt pipelines с системой валидации и алертами, обрабатывающие 1.5 млн записей в день (курсовой проект).
☑️ Cloud & Infrastructure: AWS EMR
Задеплоил и мониторил Spark jobs на AWS EMR + Glue; сократил ежемесячные расходы на обработку данных на 62% через spot-инстансов и партиционирование.
☑️ Streaming Systems: Flink, Kafka, BigQuery
Настроил автоматическую выгрузку 180 тыс. событий/мин из Kafka → Flink → BigQuery с exactly-once гарантиями (победитель хакатона)
☑️ Databases & Query Optimization: Snowflake, SQL
Оптимизировал хранилище данных в Snowflake + SQL, снизив среднее время запросов дашборда с 42 до 4 сек.
Почему это работает:
1. Раздел все еще наполнен ключевыми словами (Python, Airflow, AWS) для ATS.
2. Привлекает внимание. Раздел все еще лаконичный, но подтверждает менеджеру, что ты знаешь, как использовать технологии для реальных задач.
3. Дает мгновенный контекст: показывает масштаб (50k+ записей), среду (университетский проект, стажировка) и результат (сократил runtime)
Как составить сильный раздел с навыками в гибридном резюме:
1. Сгруппируй навыки в 3-4 группы, например: разработка конвейеров данных, облачные платформы, системы управления базами данных, моделирование и хранение данных;
2. Сопровождай каждую группу одним предложением с доказательствами;
3. Используй формулу, чтобы составить сильное описание: Глагол действия + Технология + Краткий контекст проекта + Конкретный результат/метрика
4. Будь честен. Доказательство может быть откуда угодно — личный проект, хакатон, курсовая, стажировка.
Одна строчка с цифрой из проекта перевесит десяток общих фраз.
Вариант 2: Reverse-Chronological с сильными стажировками (Только если у тебя 2+ легитные стажировки)
Если в активе есть одна или несколько сильных стажировок с реальной инженерной работой, можно использовать классический формат в обратном хронологическом порядке В таком случае нормальный сгруппированный раздел навыков внизу — fine.
Если ты где-то посередине — может одна хорошая стажировка плюс сильные академические проекты — рассмотри гибридный подход: акцентируй внимание на опыте, но чтобы заполнить пробелы, выдели один — два навыка пруфами, взятыми с личных или учебных проектов.
Не просто разбивай навыки по группам, но и придерживайся порядка:
1. Языки программирования (Python, SQL, Java)
2. Data engineering tools (Airflow, Spark, Kafka)
3. Cloud-платформы (AWS, GCP, Azure )
4. Базы данных (Postgres, MongoDB, Snowflake)
5. Все остальное (Git, Docker, Tableau)
А что насчет Soft skills? Не просто перечисляй личные качества, доказывай.
Недостаточно в разделе навыков указать “командный игрок”, “внимание к деталям” или “коммуникабельность”. Докажи это, естественно опиши в пунктах с профессиональным опытом или проектами:
● Совместно с командой из 3 data scientists вывел их фичевый пайплайн на PySpark в прод;
● Сделал обзор архитектуры ETL-конвейера и сценариев работы системы команде из 12 аналитиков и маркетологов;
● Написал runbooks и мониторинговые дашборды, используемые on-call командой
● Написал инструкции и дашборды для мониторинга, которыми пользуется on-call команда.
Что не работает в разделе навыков в 2026 году:
● Длинные списки из 20+ инструментов без структурирования (размывает ваш опыт)
● Перечисление навыков без пруфов
● Облака слов, иконки и прогресс-бары
Итог: Твой раздел навыков — это анонс твоего воздействия. Сделай так, чтобы никто не усомнился, что ты уже работал с настоящими данными.
Обзор карьеры и цели: как составить начинающему дата-инженеру
Саммари — это самое первое, что читает менеджер по найму. И во многом от этого раздела зависит, дочитают ли резюме до конца.
Сильное summary должно решать три цели для junior дата-инженера делает три вещи:
1. Говорит, кто ты
2. Доказывает, что ты уже что-то сделал
3. Показывает, что у тебя есть перспективы для развития
Шаблон для составления саммари:
Junior Data Engineer, с опытом создания [что сделал] с помощью [инструменты], достигнув [метрика]. Готов [что принесу], параллельно развиваясь в [1-2 технологии, актуальные для компании].
Слабый пример (не делай так):
"Недавний выпускник, ищущий entry-level позицию дата-инженера в технологической компании, где я могу использовать свои навыки и расти профессионально"
Это не говорит ничего о том, что ты умеешь. Удали.
Реальные примеры Саммари, которые получают интервью:
1. Младший инженер по обработке данным. Спроектировал и запустил end-to-end ETL воркфлоу на AWS Glue + Redshift, сокративших задержку в формировании отчетов с 24 часов до 2 часов. Работая над data-инфраструктурой, ставлю на первое место точность и надежность. Стремлюсь расширить навыки, в процессе освоения Delta Lake и Unity Catalog.
2. Младший дата-инженер. Создал конвейер для потоковой обработки данных с Kafka и Spark Structured Streaming (гарантия exactly-once), обрабатывающий около 1 млн. записей/день (опенсорс-проект с 3.2K звёзд на GitHub). Ищу задачи петабайт-масштаба и возможности для развития в направлении распределённых систем.
А что делать, если нет громких достижений?
Не у всех есть проект на терабайтах. Это нормально. Фокусируйся на охвате инструментов и желании учиться.
Пример саммари для резюме младшего дата инженера — если нет значительных успехов:
“Junior Data Engineer с академической подготовкой в Python, SQL и распределенных системах. Построил end-to-end ETL конвейеры данных для университетских проектов, включающих извлечение данных по API и автоматическую выгрузку в хранилища данных. Готов применять полученные навыки в продакшн-среде и параллельно осваивать оркестрацию данных и системы мониторинга”
Несмотря на отсутствие метрик и сильных достижений, этот пример работает. Потому что здесь есть честность, техническая глубина и четкий вектор развития:
Что не нужно писать в саммари
Вот некоторые фразы, которые звучат шаблонно и при этом не добавляют тебе ценности:
❌ «Страстно желающий развиваться в [Название компании]...»
❌ «Командный игрок с уверенным знанием Python...»
❌ «Мотивированный самоучка, жаждущий новых технологий...»
❌ «Стремлюсь применить навыки в [Google]...»
Это клише, которые отправляют резюме в корзину. Говори прямо, что умеешь и чего хочешь. Если роль про стриминг — упомяни стриминг. Если команда работает с облаком — говори про облако.
Как назвать: “Карьерные цели” (Objectives) или “Обзор карьеры” (Summary)?
Честно? Писать заголовок для раздела необязательно. Просто размести текст наверху перед шапкой с контактами.
Советы:
✔ Адаптируй под компанию. Не нужно переписывать все, достаточно упомянуть инструменты. Занимает 30 секунд, значительно повышает callbacks
✔ Пиши summary последним, выбрав самую сильную метрику из своих проектов.
✔ Добавляй метрики: (производительность систем, задержка, событий/день, экономия затрат, время безотказной работы).
Опыт работы: качество важнее количества
Для некоторых кандидатов это может быть открытием: раздел с опытом в резюме джуна не основной, поэтому он не должен быть большим и “глубоким”. В отличие от senior-ролей, начинающие дата инженеры должны отдавать приоритет навыкам, проектам и образованию. Раздел “Опыт” — это бонус.
Тебе не нужен длинный список должностей. Нужно 2-4 ёмких пункта, доказывающих, что ты работал в команде и приносил пользу — даже если это экономия нескольких часов рутины.
Стажировки бывают разными. Некоторые компании сразу допускают интернов к участию в реальных проектах. Другие только дают тестовые задачи и позволяют лишь изучать реальные проекты без возможности вносить свой вклад. Суть в том, чтобы честно и выгодно подать тот опыт, которые уже есть.
Вот как подать свой опыт в зависимости от типа стажировки.
Тип 1: Стажировка со средним уровнем ответственности
Самый распространенный сценарий для 2-3-месячных стажировок. Ты не вёл проект, но вносил реальный вклад под руководством прикрепленного наставника, занимаясь, в основном, рутинными задачами. Это нормально, просто будь конкретным.
Как описать опыт с ограниченным уровнем ответственности:
● Избегай пассивных формулировок формата “Я смотрел/помогал”;
● Показывай вклад через описание задач (писал SQL, добавлял тесты, строил скрипты, дебажил);
● Фокус на коллаборации: работал с дата-сайентистами, участвовал в миграции в облако…, работал в команде по оптимизации…;
● Добавляй метрики, даже если это посредственные результаты и небольшой масштаб.
Пример описания стажировки для резюме младшего дата инженера:
Дата инженер интерн | DataStream Corp | Москва | Июнь–Август 2024
● Написал скрипты на Python для валидации данных в Airflow DAGs, что позволило выявлять 200+ некорректных записей в неделю и избавило аналитиков от ручной проверки.
● Мониторил ежедневные Spark-задачи в Databricks, снизив процент падений с 8% до <1%.
● Участвовал в переносе Spark-задач на AWS Glue, сократив количество повторов с 8 до 3 в день.
Пиши коротко и без преувеличения (“принимал участие при”, “работал с”, не “вел проект”) - это позволяет показать, что у тебя есть реальный опыт. Не пиши много, хватит 3-4 пунктов.
Тип 2: Стажировка с высокой ответственностью
Ты реально что-то построил и запустил. Здесь важно быть конкретным:
● Опиши проект с самыми впечатляющими результатами;
● Опиши стек (Airflow, Spark, AWS/GCP, dbt, Kafka);
● Покажи влияние, используй сильные глаголы: “спроектировал”, “построил”, “запустил”, “оптимизировал”, “автоматизировал”;
● Метрики обязательны (записей/день, сэкономленных часов, уровень ошибок).
Пример:
Стажёр, Data Engineering | StreamData Inc. | СПб | Май–Август 2024
● Разработал и запустил DAG в Airflow для обработки ~300K записей в день, сократив время загрузки на 45%.
● Спроектировал dbt-модели для дашборда аналитиков, ускорив их работу с 30 до 5 секунд.
● Автоматизировал ETL-процесс из S3 в Redshift, убрав 90% ручных операций.
● Перевёл 12 устаревших SQL-запросов из Oracle в Snowflake, улучшив время выполнения с 45 до 8 секунд.
Здесь также нужно быть честным. Ты не заявляешь, что перестроил всю data-платформу. Ты показываешь, что можешь написать код, решающий реальные проблемы.
Список глаголов, которые позволяют показать влияние в дата инженерии
Используй глаголы, которые показывают, что ты решаешь проблемы:
● Конвейеры данных: Построил, разработал, спроектировал, внедрил, автоматизировал, задеплоил
● Оптимизация процессов: Сократил, улучшил, оптимизировал, ускорил, streamlined
● Масштаб проектов: Обработал, управлял, мониторил, поддерживал
● Командная работа: Сотрудничал, работал с, поддерживал
● Решение проблем: Отладил, разрешил, идентифицировал, устранил
Тип 3: Стажировка-знакомство
Обычно, это стажировка после третьего курса, которое сводится лишь к наблюдению и поверхностному знакомству с реальными системами в дата инженерии: изучение кода и архитектуры систем, подготовка документации, запуск тестовых задач, анализ логов и т. п.
Это нормально и все еще подходит как опыт для резюме джуниора.
Как правильно оформить такой опыт:
● Фокус на полученных знаниях (какие концепты, инструменты и workflows, с которыми ты познакомился)
● Покажи даже небольшой технический вклад (документация, SQL-запросы, тестирование, automation эксперименты)
● Привяжи задачи к технологиям (мониторинг, контроль версий, дебаггинг, моделирование данных)
Примеры bullets:
● Помогал в мониторинге и отладке пайплайнов Airflow, изучая принципы оркестрации.
● Составил документацию по lineage данных, что сократило число уточняющих вопросов от аналитиков.
Правило: Включай только опыт, который связан с инженерией данных. Подработка в рекламе или оператором в колл-центре не подходят.
Независимо от типа стажировки, всегда связывают свою работу с инженерными навыками:
● Извлечение данных
● Преобразование данных
● Моделирование данных
● Оркестрация
● Миграция в облако
● Облачные вычисления
● тестирование и мониторинг
● Оптимизация производительности
● Доступность данных
● Автоматизация сбора и преобразования данных
Образование: академическая база для начинающего инженера по данным
Для джуниора раздел «Образование» — не формальность, а фундамент. Здесь ты доказываешь, что умеешь учиться и применять теорию.
Как подать раздел “Образование”:
✔ Поставь раздел сразу после summary и навыков, если опыта мало.
✔ Начинай с основной информации: степень и специализация, название университета, локация (город), год окончания;
✔ Добавь GPA, только если он выше 4.0 для СНГ (или выше 3,0 для США, Канады, ЕС) и ты выпустился меньше двух лет назад;
✔ Добавь курсы и академические проекты, если они связаны с инженерий данных.
Акцентируй внимание на ключевых проектах — дипломе, курсовых работах, внеклассных open-sourse проектах, если есть значимые результаты в области обработки данных. Если есть конкретные результаты, выдели место в разделе “Проекты”, а также сделай отсылку в Саммари.
Пример:
Бакалавр компьютерных наук | Национальный исследовательский университет ИТМО | Июнь 2025
● Средний балл: 4.2
● Ключевые курсы: Управление базами данных, Распределённые системы, Облачные вычисления, Алгоритмы и структуры данных.
● Дипломный проект: Разработал и внедрил систему потоковой обработки данных на Apache Kafka и Spark для анализа социальных медиа. Обеспечил задержку менее секунды при обработке 2 млн записей.
Сертификаты показывают инициативу
Сертификаты и дополнительное обучение тоже важны — они показывают, что ты продолжаешь развиваться и владеешь актуальными инструментами и подходами.
Не нужно подробно описывать программу обучения, достаточно перечислить сертификаты с указанием года выдачи. Дополнительные курсы на платформах типа Coursera или Udacity можно указать в отдельной секции.
Пример:
● Data Engineering Professional Certificate — Google Cloud Platform (2024)
● AWS Certified Data Engineer — Associate — Amazon Web Services (2025)
Сильный раздел проектов — докажи навыки цифрами
Проекты — раздел, где ты можешь не только доказать, что знаком с инструментами, но и показать, насколько глубоко овладел ими. От тебя не ждут энтерпрайз масштаба, но даже личные или академические проекты описывай так, как реальный опыт: с метриками и контекстом (описанием, какая цель, какую проблему решает).
Сравни:
Размытый пример:
❌ "Работал над конвейером данных, собирающих информацию о продажах"
Сильный пример:
"Построил ETL пайплайн, обрабатывающий 50,000+ транзакций ежедневно, сократив задержку в формировании отчетом по продажам с 2 часов до 15 минут"
Второй вариант не просто заявляешь что знаешь, как строить пайплайы, он подтверждает, что ты можешь решать конкретные задачи с их помощью.
Как правильно показать результаты даже в небольших учебных проектах — универсальный шаблон
Описывай проекты по такому шаблону:
[Глагол действия] + [конкретная задача] + [инструменты/технологии] + [результат]
Это не правило, а лишь пример. Можно адаптировать шаблон под конкретный проект.
Примеры описания проектов:
● Автоматизировал валидацию данных с помощью Python и Great Expectations, сократив ручную проверку на 6 часов в неделю
● Оптимизировал SQL-запросы для дашборда, снизив время загрузки с 30 секунд до менее 5
● Разработал Airflow-workflow для загрузки данных из 3 внешних API, обрабатывающий 100K+ записей в день с точностью 99,5%
Даже академические проекты отлично ложатся в этот формат:
● Построил рекомендательную систему на TensorFlow с точностью предсказаний 85% на датасете с рейтингами фильмов
Указывай даже проекты небольшого масштаба. 10 ГБ данных в университете или 5 источников в стажировке — это тоже опыт.
Важно не «насколько много», а насколько четко ты показываешь результат.
Метрики, которые хорошо работают для junior data engineer:
● Объем: количество записей, размер данных (GB/TB), число источнико
● Производительность: время ответа запросов, снижение lзадержки формирования отчетов, скорость выгрузки данных
● Эффективность: сэкономленные часы, уменьшение ручных шагов, снижение числа ошибок
● Масштаб и надёжность: uptime, точность отчетов, число таблиц, количество интегрированных API
Совет: Смени мышление с «что я делал» на «что я принес».
«Фраза “отвечал за качество данных” — пассивна. А “провёл валидацию 50 таблиц, выявив и устранив 200+ аномалий” сразу показывает влияние и владение стеком».
Цифры не должны впечатлять. Они просто должны быть реальными и конкретными.
"Extras", которые выделяют тебя
Добавь в резюме дополнительные разделы. Это может быть участие в хакатоне, волонтерская работа или любой другой проект, которые выделяет тебя на фоне других кандидатов.
Если у тебя несколько достижений, создай отдельный раздел с достижениями.
Итог
Резюме младшего инженера по данным должно давать менеджеру по найму чёткое ощущение, что:
● ты работал с реальными пайплайнами, инструментами и датасетами;
● понимаешь, как инженерная работа создает измеримую ценность;
● готов развиваться и быстро осваивать новые навыки.
Держи резюме лаконичным, честным и делай так, чтобы каждая строка что-то доказывала.
Пример резюме Junior Data Engineer №4
Маркус Чен
Младший инженер по данным
Москва | (999) 555-0147 | marcus.chen@email.com | GitHub: github.com/mchen-data
Профиль
Младший дата-инженер с практическим опытом построения ETL пайплайнов с использованием Python, SQL и Apache Airflow. Разработал автоматизированную платформу для обработки данных, сократившую ручную работу аналитикам и маркетологам на 4 часа еженедельно. Готов применять навыки по настройке облачных систем для распределенной обработки данных.
Технические навыки
Data Pipeline Development:
Построил end-to-end ETL пайплайн с использованием Python и Airflow, обрабатывающий 100K+ ежедневных записей из REST APIs, применил transformation logic и загрузил в PostgreSQL (University capstone project)
Cloud Infrastructure: Запустил среда для обработки данных на AWS с использованием S3 для хранения, Lambda для бессерверной обработки и Glue для оркестрации(Стажировка в DataWorks)
Stream Processing: Реализовал Kafka consumer, обрабатывающий 8 тысяч real-time событий в секунду с мониторингом и error handling (Личный проект: github.com/mchen-data/stream-processor)
Языки и инструменты: Python, SQL, Scala | Airflow, Spark, Kafka | PostgreSQL, MongoDB | AWS, Docker, Git
Проекты
Real-Time Analytics Dashboard
Построил потоковый пайплайн с использованием Kafka и Spark Structured Streaming для обработки данных в реальном времени. Реализовал сбор информации из нескольких источников и записал результаты в Redis, обеспечив sub-second query response times для 50K+ событий ежедневно.
Cloud Data Warehouse
Спроектировал star schema на Amazon Redshift, организовав 15 GB e-commerce данных. Оптимизировал запросы, сократив execution time с 35 секунд до 6 секунд, улучшив productivity аналитиков.
Опыт работы
Data Engineering Intern | DataWorks Inc., Москва
Июнь 2024 — Август 2024
● Автоматизировал систему проверку качества данных с использованием Python и Great Expectations, сократив количество ручной работы на 40%
● Построил monitoring dashboard, трекающий pipeline health по 6 data sources, обеспечив faster incident response
● Поддерживал senior-инженеров в процессе миграции legacy MySQL запросов в Snowflake, улучшив среднюю скорость обработки query запросов на 65%
Образование
Бакалавр Computer Science | МГУ
Выпуск: Май 2024 | GPA: 3.6
Релевантные курсы: СУБД, Распределенные вычисления, Машинное обучение (ML), Облачная архитектура
Сертификаты: AWS Certified Data Analytics — Specialty | Google Cloud Professional Data Enginee
Как оптимизировать резюме для ATS
В большинстве компаний использую ATS (Applicant Tracking System), которые отсеивают нерелевантные резюме, выполняя рутинную работу вместо рекрутера.
Важно понимать одну вещь: большинство ATS никого автоматически не отклоняют. Это не злая машина, а по сути умная база данных. Она:
● парсит текст резюме,
● сохраняет его,
● позволяет рекрутерам искать и фильтровать кандидатов по ключевым словам.
Если ты не получаешь приглашение на собеседование, чаще всего причина не в том, что:
● твои навыки не совпали с тем, что искали;
● резюме не показывает релевантный опыт достаточно ясно;
● на вакансию пришло много более сильных кандидатов;
● рекрутер искал конкретное ключевое слово, которого у тебя просто нет в тексте.
Поэтому твоя цель — не пытаться перехитрить ATS, а сделать резюме максимально понятным для ПО и удобным для рекрутера, полностью совпадающим с описанием вакансии. Как этого добиться?
Оптимизация по ключевым словам
1. Используй ту же терминологию, что и в описании вакансии
Внимательно прочитай описание вакансии и выдели технические требования. Если ты работал с этими инструментами — используй ровно те же слова.
Не пиши «workflow orchestration», если в вакансии написано Airflow. ATS и рекрутер ищут конкретные совпадения.
2. Придерживайся стандартных заголовков разделов
Используй стандартные названия для раздела, привычные для менеджеров по кадрам:
● Опыт работы (Work Experience)
● Проекты (Projects)
● Профессиональные навыки (Technical Skills)
● Образование (Education)
Избегай креатива вроде “Карьерная история” (“My Journey”) или “Технический арсенал” (“Technical Arsenal”). ATS их может не распознать, а рекрутера они сбивают с толку.
3. Встраивай ключевые слова естественно
Простое перечисление всех ключевых слов выглядит странно и может вызвать подозрение, что ты просто оптимизировал резюме, чтобы пройти парсер.
Вместо этого старайся максимально подробно описать свою работу: с цифрами, технологиями, инструментами, контекстом. Тогда слова естественно появятся в твоем резюме.
Хороший пример:
Построил data pipelines с использованием Apache Airflow для оркестрации ETL-задач.
Ключевые слова есть, и они несут смысл.
Форматирование, которое дружит и с ATS, и с людьми
Сложный дизайн часто ломает парсинг. Поэтому:
✔ Один столбец. Без таблиц, текстбоксов, сайдбаров и изображений с текстом.
✔ Стандартные шрифты: Arial, Calibri, Helvetica, Times New Roman. Размер: 10–12 pt для текста, 14–16 pt для имени.
✔ Оставляй свободное пространство. Оставь нормальные отступы (1 - 1,5 см), широкий поля (1,5–2 см), используй интервал 1,15-1,5 улучшают читаемость.
✔ Полужирный шрифт — только для имени, заголовков и должностей. Не выделяй случайные слова.
✔ Формат файла — PDF, если в вакансии не указано Microsoft Word (.docx).
✔ Название файла должно выглядеть профессионально: Имя_Фамилия_DataEngineer_Resume.pdf
Совет: Тщательно вычитывай резюме перед отправкой.
Опечатка в контактах, названии ключевой технологии — это красный флаг. Это сигнал, что ты недостаточно внимателен к деталям.
Часто задаваемые вопросы FAQ
У меня вообще нет опыта, даже стажировок?
Пропусти раздел с опытом, удели больше внимания проектам и образованию.
Сильный учебный или дипломный проект ценнее, чем нерелевантные подработки. Резюме должно показывать способность строить data-решения, а не просто рассказывать, «где ты работал».
Должен ли я прикреплять ссылки?
Нет. Не в резюме.
“Ссылки доступны по запросу” — устаревший фильтр из прошлого. Если HR-у нужны рекомендации, он попросит их (обычно после интервью). Лучше используй это место для более подробного описания проектов или оставь пустым.
Как насчет хобби или интересов?
Только если они реально усиливают профиль.
Вот тест:
❌ “Чтение, походы, путешествия” — неуместно;
✅ “Личные проекты по программированию — актуально, можно указать, если осталось много пустого места на странице;
✅ “Шахматы (чемпион области)” — если подаешь заявку на стажировку, укажи, показывает дисциплину;
✅ “Запустил домашний сервер с хостингом облачной системы для обработки данных” — точно включи, ценно даже миддла
Простой тест: делает ли это хобби тебя более сильным дата-инженером? Если да — оставляй. Если нет — отбрось.
Нужно ли фото в резюме?
Нет. Для tech-ролей в СНГ, Северной Америке, на Ближнем Востоке фото не нужно и выглядит непрофессионально. Оставь фото для LinkedIn.
Нужно ли сопроводительное письмо?
Добавь если:
● система подачи заявки просит его;
● вакансия прямо указывает, что оно нужно.
Если пишешь — коротко укажи:
1. Почему эта компания и роль;
2. Один сильный проект с результатом;
3. Чем хочешь быть полезен и чему готов учиться.
Нужна помощь в составлении сопроводительного письма? Воспользуйтесь конструктором EngineerNow.org.
В каком формет сохранить файл: PDF или Word doc?
По умолчанию используй PDF. Он гарантирует, что форматирование сохранится на разных устройствах и при печати. Исключение, если в вакансии указан конкретный формат, например, .docx или .rtf.
О чем можно соврать в резюме?
В резюме нужно быть честным. Но есть несколько серых зон, где допустима грамотная подача (а не выдумки). В этом коротком видео разбираем, что именно можно и нельзя делать.
🤖 А твое резюме точно готово? Получи мгновенную оценку
Ты написал резюме, но пройдет ли оно ATS? Выделяет ли оно нужные навыки? Прежде чем нажать «отправить», получи профессиональный анализ за секунды.
Анализатор резюме на engineernow.org проверяет резюме по тем же принципам, что и ATS.
Что дает проверка резюме:
✓ Оценка оптимизации для ATS. Узнаешь, как парсится резюме, увидешь проблемы форматирования, недостающие ключевые слова и слабые разделы, которые могут отфильтровать тебя.
✓ Персонализированные рекомендации: Получи конкретные предложения, как улучшить раздел проектов, усилить пункты с достижениями и лучше соответствовать описанию вакансии. Мы выходим за рамки базовой проверки орфографии и ключей.
✓ Бенчмарк конкурентоспособности: Узнай, как длина твоего резюме, подбор слов и структура соотносятся с успешными кандидатами. Отслеживай свой прогресс со временем.
✓ Конфиденциальность гарантирована: Твои данные в безопасности. Мы соблюдаем строгую политику конфиденциальности и не передаем твою информацию сторонним лицам или компаниям.
Больше не нужно действовать методом проб и ошибок, упуская отличные возможности.
Загрузи резюме и добавь описание вакансии. Анализ меньше, чем за минуту!
Заключение
Теперь у тебя есть все инструменты, примеры резюме и стратегии для создания сильного резюме для младшего инженера по обработке данных.
Помни:
● Показывай конкретные достижения с цифрами
● Адаптируй под каждую вакансию
● Держи чистым, честным и сфокусированным на результатах
● Акцент на проектах, которые доказывают, что ты умеешь работать со стеком
Твое первое место работы дата-инженером ждет.

Written by
Недавние Посты

Опуб: 17 апр. 2026 - Обно: 01 мая 2026
8 мин. чтения
Основные плюсы, минусы и заработная плата Инженеров

Опуб: 29 янв. 2026 - Обно: 01 мая 2026
61 мин. чтения
Резюме строительного электрика (электромонтажника): примеры, структура и советы, которые работают в 2026
Опуб: 25 дек. 2025 - Обно: 01 мая 2026
6 мин. чтения
Видео Резюме Инженера: как обойти 90% инженеров на рынке труда в 2026