30 min. read
How to Craft Data Engineer Resume: Comprehensive Guide and Tips to Get You Hired
Are you applying for data engineering jobs but getting rejected? This challenge isn’t just for recent graduates. Even experienced data engineers with strong qualifications can struggle. Often, the real problem isn't your qualifications, but how you present them, especially on your resume.
In this guide, I'll show you how to write an effective résumé for a data engineering position. You’ll learn which sections to include, how to highlight your technical skills and achievements, and how to demonstrate your value to convince hiring managers that you're the ideal candidate. You'll also find examples and templates, common mistakes to avoid, and actionable tips to make your résumé stand out.
Crack the Code to FAANG & High-Paying Data Engineering Roles.
Ready to supercharge your engineering career and land coveted positions at tech giants like Apple or Amazon – even without decades of experience? The Engineer-Millionaire™ course is your key. Designed for driven engineers (from ambitious juniors to seasoned pros seeking breakthrough growth), this course delivers the proven strategies to:
- Master in-demand skills that make you irresistible to top tech firms.
- Dominate technical interviews and sell your expertise with confidence.
- Stay driven and strategic, turning routine tasks into stepping stones for massive career advancement and earning potential.
What This Guide Will Help You Do
● Understand the anatomy of a successful data engineer resume
● Learn how to write your resume to pass both ATS and human screening
● Tailor your resume for both entry-level and senior data engineering roles
● Avoid common mistakes that sink even qualified applicants
● Use action verbs and data to showcase your impact
● Build a resume that highlights your technical skills and business value
Let’s dive in.
Why Data Engineers Need a Strong Resume
In today’s data-driven world, businesses depend on accurate, scalable, and timely data to make decisions about everything from marketing to logistics to product development. Without robust data systems, companies lose their competitive edge. This is why data engineers are in high demand across industries.
Unlike data analysts, who focus on interpreting data, data engineers design, build, and maintain the infrastructure that enables data processing. They create scalable data pipelines, manage databases, and provide analysts with access to reliable, high-quality data via tools such as Apache Spark, AWS, and SQL.
Data engineering roles are valuable, and employers have high expectations. But with great responsibility comes great expectation. They seek candidates with deep technical expertise, experience with big data and cloud platforms, and the ability to solve complex business issues. Since errors in data processing can be costly, hiring managers look for professionals who align with their company’s needs and deliver accurate, actionable results.
What does this mean for job seekers? You may have a degree from a top university, such as MIT or Stanford, and have mastered tools like Python, Tableau, and Snowflake. You may also have built sophisticated data pipelines. However, if your resume doesn't effectively showcase your abilities, you may have difficulty standing out.
The good news is that you can stand out, even with limited experience or as a recent graduate. This article will show you how to craft a resume for Data Engineer that does just that.
Resume Structure for Data Engineers
Some candidates believe a resume is just a list of contact information, technical skills, and work history packed into a stylish template. However, a resume for a data engineer is more than just a document—it’s your personal marketing tool.
Your goal? Grab the recruiter’s attention within the first few seconds. Before that, though, your resume must pass through an Applicant Tracking System (ATS), which scans resumes for keywords and structure. This means your data engineer CV must be clean, concise, and properly formatted while clearly showcasing your technical skills, problem-solving abilities, and business impact.
Here’s a proven resume structure tailored specifically for data engineers:
1. Contact Information
2. Resume Summary or Objective
3. Skills
4. Work Experience
5. Education
6. Projects (Optional)
7. Certifications
8. Languages (Optional)
9. References (Optional)
10.Additional Sections (Optional)
1. Contact Information: Keep It Clean, Clear, and ATS-Friendly
Place the following details at the top of your data engineer resume:
- Full Name
- Job Title or Specialization (e.g., Data Engineer, Cloud Data Engineer)
- Email Address (professional, e.g., john.doe@email.com)
- Phone Number
- LinkedIn Profile
- GitHub or Portfolio Link (optional, to showcase projects)
- Location (City, State – optional but recommended if stated in the job description)
Your contact header should be professional and concise and placed at the very top of your resume. Do not split this section into multiple columns. Avoid overly stylized resume templates that prioritize aesthetics over functionality. While a multi-column design might look sleek, it can confuse ATS software by blending your contact details with other sections, such as your summary. This can lead to critical information being misinterpreted or overlooked entirely, which could result in your application being disqualified.
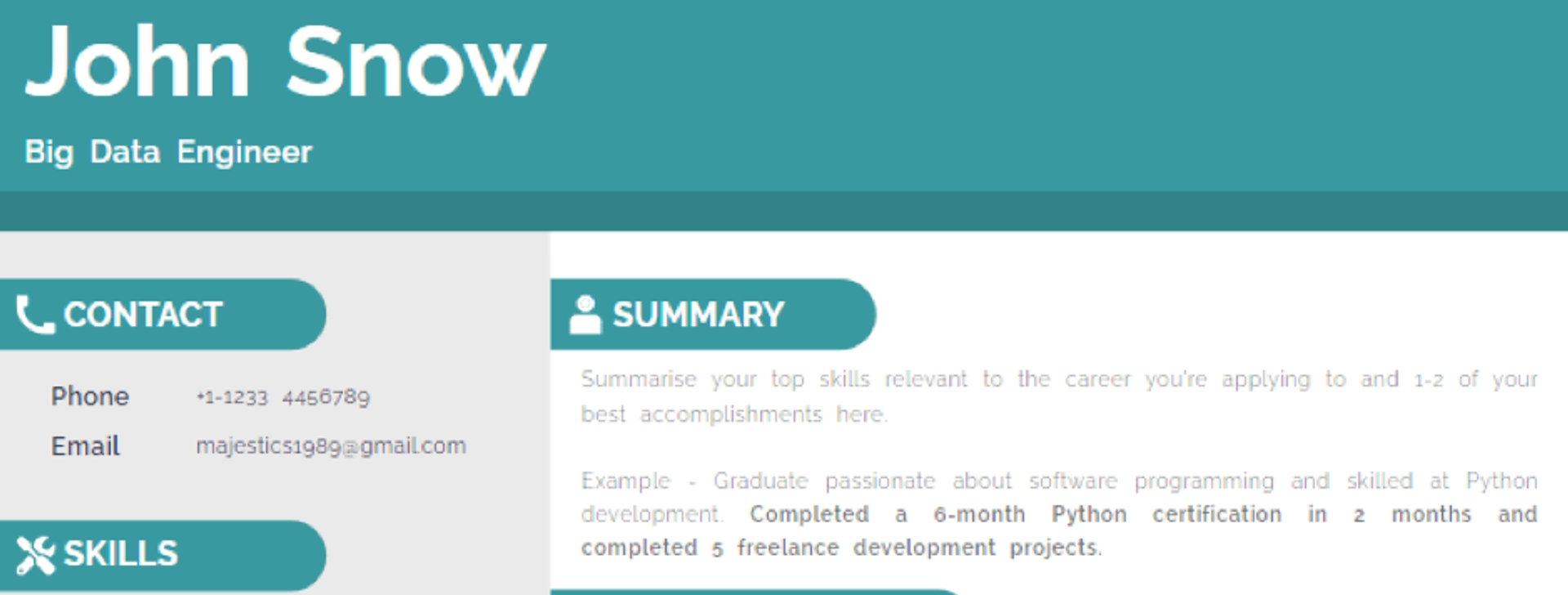
This is not the best design for an engineer's resume. While it looks nice, when scanned through ATS, the information from the contacts column can get mixed in with the summary. This can cause your application to be misread and dismissed.
In the contact section, always use your full legal name—no nicknames or aliases. Your email address should also be professional. For example, use jane.dow@mail.com instead of data_guru123@email.com.
Include in your resume a link to your LinkedIn profile—this is essential. According to recent data, around 87% of recruiters in North America, Europe, and the Middle East review LinkedIn profiles as part of the hiring process. If you don't have a profile, create one and complete your details. Then, start building your network.

Example of a successful contact section
You may also add a link to a personal website, online portfolio or share other resources that showcases your projects in data engineering. Technical professionals should include a GitHub profile or similar professional community page to give recruiters direct access to their work and reinforce their credibility.
2. Professional Summary or Career Objective
This section of data engineer resume is your elevator pitch: a concise overview of 3–5 sentences that hooks the recruiter. Tailor it to each job description, emphasizing why you’re the ideal candidate and the value you would bring to the company.
The summary is more relevant for experienced Data Engineers: Highlight your expertise, key skills, and quantifiable accomplishments.
Example: "Data Engineer with over five years of experience designing scalable ETL pipelines using Apache Spark and AWS. Reduced data processing latency by 40% at [Company Name] by developing automated workflows and implementing optimized data models."
The Career Objective is best for entry-level Data Engineers. Limited experience can be offset with a strong academic background, enthusiasm, and a willingness to develop and learn new skills, as well as adapt to the specifics of the company's processes. Example: "Rutgers University graduate with a degree in Computer Science and hands-on experience with Python and SQL. Looking to apply data pipeline development skills to support business intelligence at [Company Name]."
Pro tip: Incorporate keywords such as "ETL," "data pipelines," "AWS," "big data," or "real-time processing" to increase your ATS match.
3. Skills
List your skills concisely and organize them by category without providing lengthy explanations. Recruiters scan this section quickly to assess your qualifications. Prioritize the skills mentioned in the job description that align with the role.
Common Technical Skills for Data Engineers:
● Programming Languages: Python, Java, Scala, SQL
● Big Data Technologies: Apache Spark, Hadoop, Kafka, Airflow
● Databases: MySQL, PostgreSQL, MongoDB, Oracle, Snowflake
● Cloud Platforms: AWS (Redshift, S3), Azure, Google Cloud Platform (GCP)
● ETL Tools: Informatica, Talend, Apache NiFi
● Data Visualization Tools: Tableau, Power BI
● Other: Data modeling, data warehousing, machine learning basics, Docker, Git, Kubernetes, Excel
For engineers, soft skills are usually secondary. However, for data scientists, soft skills are worth mentioning and can be listed separately if extensive. List them without providing a detailed description.
Actual soft skills for data engineer:
● Problem-solving under pressure
● Cross-functional collaboration
● Decision-making under pressure
● Communication and teamwork
● Project management
● Time management and ownership
Tip: Show how you applied your skills in the experience or projects section to confirm your expertise. For example: "Collaborated with data analysts to optimize analytics workflows," or "Developed ETL pipelines using Python and SQL."
4. Work Experience:
This section of your resume is where you demonstrate your technical skills and capabilities. Hiring managers want to see the impact you had, measured by outcomes, metrics, and results—not just what you did.
Use a reverse chronological order and list your most recent roles first. Each entry should include:
● Job title (e.g., data engineer, senior data engineer)
● Company name and location (city and state)
● Employment dates: indicate the month and year (e.g., January 2022 – present)
● Key responsibilities, accomplishments, and tasks. Explain how you improved company processes. Use three to five bullet points for each role, emphasizing impact over duties.
Tip: Each bullet point should start with an action verb and ideally follow this formula:
[Skill/Tool] + [Action] + [Impact]
Entry-level candidates with limited experience may use the functional resume format. Functional resume emphasizes relevant projects or internship tasks rather than providing a detailed work history, which could draw attention to your lack of experience. Focus on the problem, your solution, and the results.
Experience Section Example:
Senior Data Engineer
TechCorp, San Francisco, CA
June 2020 - Present
● Design and implement scalable data pipelines using Apache Spark and AWS S3 to process over 1 TB of data daily and support business intelligence initiatives.
● Automated data validation workflows with Airflow, reducing data errors by 25% and ensuring high-quality analytics outputs.
● Collaborated with cross-functional teams to integrate real-time streaming data with Kafka, enabling faster decision-making for marketing campaigns.
● Mentored a team of 3 junior data engineers, improving team efficiency by 15% through knowledge-sharing and code reviews.
Data Engineer
DataSolutions Inc., Seattle, WA
Jan 2018 - May 2020
● Built ETL pipelines using Python and SQL, transforming 500GB of unstructured data into actionable insights for sales teams.
● Optimized Hadoop-based data processing workflows, cutting runtime by 40% and saving $50K in annual infrastructure costs.
● Developed Tableau dashboards to visualize key performance metrics, increasing stakeholder engagement by 20%.
Tips to Make This Section of Resume Stronger:
- Quantify your achievements. Use metrics to demonstrate your impact. Example:
"Developed a real-time data pipeline with Apache Kafka, reducing latency by 50%."
- Use the Skill-Action-Result (SAR) framework. Specify the technology, action, and business outcome.
Example:
"Automated ETL processes using Python and Redshift, saving 20 hours of manual work weekly."
- Tailor to the job: Highlight the tools and skills listed in the job description.
- Use action-oriented language. Replace vague terms like "managed" with "designed," "optimized," or "implemented." Strong verbs catch recruiters’ attention and demonstrate ownership. Example:
"Optimized MySQL database performance, reducing query response time by 30%."
These tips are also relevant for the projects and education sections.
5. Education
List your academic degrees, starting with the highest level achieved. If you hold several degrees at the same level but in different fields (e.g., a bachelor's in Web Development and another in Data Engineering), list the one most relevant to the job you're applying for first.
Experienced data engineers can keep it brief:
- Degree name (e.g., Bachelor of Science in Computer Science)
- University name and location
- Graduation date (month and year)
Entry-level Data Engineers and recent graduates should provide more detail.
- GPA (if above 3.0 for U.S./Canada)
- Relevant coursework (e.g., Data Structures, Algorithms, Database Systems)
- Academic projects or lab work, related to the job
- Capstone projects or theses that align with the job
A more detailed description of your academic background demonstrates your training and ability to work with specific tools or technology stacks. If you have limited work experience, move the Education section higher in your resume—just below Skills.
Tip: Apply the same principles as in the experience section: quantify results, use action verbs, and tailor your response to the job description.
Here is an example of an education section:
B.S. in Computer Science | Rutgers University | 2023
- GPA: 3.8/4.0
- Relevant Coursework: Data Structures, Database Systems, Big Data Analytics
- Capstone Project: Built an ETL pipeline using Python and PostgreSQL to analyze customer data, reducing processing time by 25%.
6. Projects (Optional)
For entry-level engineers, this section of the resume can compensate for a lack of professional experience by demonstrating your ability to work with data pipelines, cloud platforms, and real-time processing systems. This can include work completed in college or an engineering club. Mention:
- Academic projects or theses relevant to the job
- Extracurricular work, such as hackathons or robotics clubs
- Volunteer projects (e.g., optimizing a nonprofit’s database).
- Internship projects
- Personal projects that prove data pipelines, databases, or cloud skills
Experienced engineers can use this section to highlight significant achievements or diverse expertise.
For each project, include:
- Project title
- Role or context (e.g., "Personal Project," "Capstone Project")
- Dates:
- A description of what you built, the technologies used, and the business impact.
Tip: Include links to your GitHub repository or portfolio to showcase your work.
Example:
Real-Time Stock Market Data Pipeline
Personal Project · GitHub
January 2023 – March 2023
● Designed a streaming data pipeline using Apache Kafka and Python to ingest stock market data in real-time.
● Configured MongoDB for scalable storage and fast querying.
● Created interactive Tableau dashboards to visualize key metrics, used by over 50 users.
7. Certifications:
Certifications confirm your knowledge, especially when you lack formal experience. They show to recruiters that you are proactive and knowledgeable about modern data technologies. Thus, they increase your value as a specialist and allow you to stand out from other candidates.
There is no need to describe certifications in detail. List them concisely. What to include:
- Certification Name
- Issuing Organization
- Year Earned
Relevant certifications for data engineer:
● Google Certified Professional Data Engineer
● AWS Certified Data Engineer - Associate
● AWS Certified Big Data - Specialty
● IBM Certified Data Engineer - Big Data
● Microsoft Certified: Azure Data Engineer Associate (DP-203)
● Cloudera Certified Professional: CCP Data Engineer
● Databricks Certified Data Engineer Associate
Tip: In your Work Experience or Projects section, mention how you applied the knowledge gained through certification. Example:
"Used AWS Big Data certification skills to optimize Redshift queries, cutting monthly cloud costs by 15%."
8. Languages (Optional)
If you are applying to international teams or multilingual companies, please list the languages you speak and your level of proficiency in your data engineer resume.
Example:
- English: Native
- Spanish: Fluent
- Russian: Advanced
9. References (Optional)
If possible, please attach a link to the recommendation letter. If relevant, you may also provide contact information for a mentor, tutor, supervisor, or other person who can attest to your abilities as a data engineer and provide a good reference.
10. Additional Sections (Optional)
List any additional information that could confirm your qualifications as a data engineer.
- Conferences attended
- Patents or publications
- Professional development courses
- Hackathons or competitions
Tip: Be honest. Only include experiences that you can confidently explain in an interview.
Resume Formatting and Design Tips for Data Engineers
Keep your data engineer resume concise and well-organized. Use a single-column layout to ensure accurate ATS parsing.
Key formatting tips:
- Length: One page is ideal for most candidates. Two pages is acceptable if you have 10+ years of experience or a long project list.
- Font: Use modern, easy to read fonts like Calibri, Arial, Roboto, or Times New Roman. Stick to 10–12 pt for body text. Section headings can be in bold or in the Rubik Mono font.
- Margins: Standard 1-inch (2.5 cm) margins work best. If needed, reduce slightly to fit content (no less than 0.75 inches). Leaving enough space on the page makes the document look professional and easier to read.
- File format: Save and submit your resume as a PDF — it will display correctly on all devices. Some job descriptions may require you to send the file in Microsoft Word (.doc or .docx) or Rich Text Format (.rtf).
- Consistent Formatting: Use uniform headings, date formats, and section styles. Avoid columns, tables, and images. Stick to a one-column layout.
Tip: Use a hybrid resume format that combines the experience and projects sections. This will help demonstrate that you meet the requirements of the job posting, even if you have limited career experience.
Tailoring Your Resume to the Job
Every job posting is unique. To increase your chances of being selected, customize your data engineer resume for every application.
Here's how to do so effectively:
● Examine the job description.
Identify the keywords, skills, and tools that the employer emphasizes. For example, if the description says "experience with AWS Redshift", be sure to highlight the relevant project.
● Customize the summary.
Emphasize experience and goals that align with the company's expectations. For example, if the focus is on real-time analytics, demonstrate your experience with Kafka or Spark Streaming.
● Reorder your skills.
Place the most relevant tools (those listed in the job description) at the top of your "Skills" section. These changes will increase your chances of catching the recruiter's attention.
● Update the bullets in your work experience section.
Focus on technologies and outcomes relevant to the role. For instance, if knowledge of data warehousing systems is required, emphasize your experience with Snowflake, Redshift, and BigQuery.
Example tailoring for a job posting:
🧾 Job Requirements: "Experience with streaming data processing using Apache Kafka."
✅ Sample resume adaptation: "Developed a streaming data pipeline with Kafka and Spark, processing over 10 million events daily for real-time customer analytics."
Common Mistakes to Avoid
These typical resume mistakes will send your application to the "Rejected" folder:
● One resume for every job
Don't send a generic resume. Each employer has different requirements and uses different technologies. Tailor your resume to each job opening. This allows you to emphasize the necessary skills and experience.
● Overusing Technical Jargon
Don't turn your resume into a technical manual. While it's crucial to use professional terms like ETL, Hadoop, and Kafka, ensure your resume is clear to recruiters without a technical background.
● No measurable impact.
Avoid vague statements like “improved efficiency.” They do not clearly demonstrate your accomplishments. Use data and numbers. For example, write “Optimized MySQL queries, reducing response time by 30%.”
● No soft skills
Data engineering is about more than just code. It requires close collaboration with analysts, product managers, and leadership. Therefore, it is important to show your strengths in collaboration and communication.
● Unrelated Experience.
If you have experience in other field, only include tasks that demonstrate relevant skills like data processing, automation, or scripting.
Tip: Before sending out your resume, have someone outside of IT read it. If they understand your impact, a recruiter will too.
Tips for Entry-Level Data Engineers
If you're just starting a career in data engineering — for example, if you're a recent graduate or are transitioning from another IT industry — focus on the skills you already have.
Here are some tips to make your resume stronger:
● Showcase your student or personal projects.
Have you worked on Big Data coursework, built an ETL pipeline, or worked with databases? Write about it! While it's not a substitute for experience, it's a good way to demonstrate your level of preparation and practical skills.
● Add certifications.
Taking additional education courses and earning certifications, such as Google Professional Data Engineer or AWS Certified Data Analytics, demonstrates your initiative and knowledge of current technologies.
● Mention transferable skills.
If you have experience as a data analyst or software developer, highlight your overlapping strengths, such as your knowledge of SQL, scripting, automation, and BI tools.
● Use a Functional Resume Format.
Prioritize skills and projects over job history to demonstrate capability.
Example of an experience section on a data engineer intern resume:
Data Engineer Intern
TechStartup, remote
June 2024 - August 2024
● Wrote Python scripts to automatically extract and preprocess data from external APIs (volume - 100k+ records per day).
● Designed and deployed a MySQL database to store client data, speeding up SQL queries by 20%.
● Collaborated with analytics team to build reporting dashboards in Power BI - improved visualization of key sales metrics.
Tips for Senior Data Engineers
If you’re applying for a senior or lead role, your resume needs to go beyond tools—it should show business impact, architecture design, and leadership from previous roles.
Highlight Leadership:
Mention mentoring, team coordination, or project leadership. Example: “Led a team of 5 engineers to build an AWS-based data warehouse, cutting infrastructure costs by 30%.”
Emphasize Scalability:
Highlight experience with big data, cloud platforms, or CI/CD pipelines. Example: “Designed a Kafka-Spark streaming pipeline, processing 50M+ events daily.”
Show Business Impact:
Quantify how your work improved company metrics. Example: “Implemented a Snowflake data warehouse, reducing report generation time by 25%.”
Example: Senior Data Engineer Experience Section
Senior Data Engineer
InnovateTech, Inc., San Francisco, CA
March 2020 – Present
- Designed a scalable data pipeline using Apache Kafka and AWS Redshift that handles over 100 million daily transactions.
- Mentored a team of four junior engineers, improving team productivity by 15%.
- Optimized data warehouse performance, reducing query times by 40% and saving $50,000 annually.
How to Pass ATS: Strategies to Optimize Resumes
Many companies use ATS (Applicant Tracking Systems) to quickly filter out irrelevant applications. Here are some tips to help you pass ATS filters:
● Include keywords from the job posting, such as ETL, data pipeline, and cloud platforms, in the summary, education, and experience sections. The system scans the document for job-specific terms and marks your resume as relevant.
● Avoid Complex Formatting: Stick to a single-column layout without tables or images. A simple structure is easiest for the machine to read.
● Maintain a uniform design for headers and sections. Using different formatting styles for each section will make the resume appear unprofessional and difficult to read for both the applicant tracking system (ATS) and the HR manager.
● Expand acronyms and abbreviations, at least the first time they are used. For example: "Extract, Transform, Load" (ETL)—this increases the likelihood that the ATS will recognize the term correctly.
● Repeat key terms. Include important phrases in various sections, such as the summary, skills, and experience sections.
Data engineer resume example
Below is an example resume for a Junior and mid-level data engineers that includes best practices.
Resume example #1 for Junior Data Engineer
Michael Carter
Data Engineer
michael.carter@email.com | (512) 555-1234 | linkedin.com/in/michaelcarter | Austin, TX | github.com/michaelcarter
Career Objective
Recent University of Texas at Austin graduate with a passion for building data solutions and programming skills in Python and SQL. Proficient in creating ETL pipelines and working with data scientists to support business intelligence. Eager to leverage hands-on experience from internships at IBM and Dell Technologies to contribute to data-driven decision-making at a forward-thinking company like Amazon.
Skills
Technical Skills:
● Programming Skills: Python, SQL, Java
● Big Data Technologies: Hadoop, Spark, Apache Airflow
● Databases: MySQL, PostgreSQL, NoSQL (MongoDB)
● Cloud Platforms: AWS (S3, Redshift), Google Cloud Platform
● ETL Tools: Apache NiFi, Talend
● Data Visualization: Tableau
Soft Skills:
● Problem-solving
● Cross-functional collaboration
● Analytical thinking
● Communication
Projects
Real-Time Data Pipeline for Customer Analytics | University Capstone Project | 2025
● Designed and implemented an ETL pipeline using Hadoop, Spark, and Python to process complex data sets, handling 500K+ customer records daily.
● Collaborated with data scientists to integrate analytics into a Tableau dashboard, providing actionable insights for a simulated e-commerce platform.
● Deployed the pipeline on AWS S3, reducing data processing time by 20%.
Inventory Optimization Dashboard | IBM Internship Project | Summer 2024
● Developed a data solution using SQL and Python to automate data extraction and transformation for inventory reports, improving efficiency by 15%.
● Utilized PostgreSQL to manage large datasets and created visualizations in Tableau to support operational decision-making.
● Worked with a cross-functional team to ensure data accuracy and alignment with business needs.
Customer Segmentation Model | Dell Technologies Internship Project | Summer 2023
● Built an ETL pipeline with Apache NiFi and AWS Redshift to process customer data, enabling real-world segmentation for marketing campaigns.
● Wrote Python scripts to clean and transform data, reducing processing errors by 10%.
● Presented findings to stakeholders, showcasing data-driven insights for strategic planning.
Education
B.S. in Computer Science | University of Texas at Austin | May 2025
● GPA: 3.7/4.0
● Relevant Coursework: Database Systems, Big Data Analytics, Algorithms, Machine Learning Basics
● Capstone Project: Developed a real-time data pipeline (see Projects section).
Certifications
● AWS Certified Data Analytics – Specialty | Amazon Web Services | 2024
● Google Data Analytics Professional Certificate | Coursera | 2023
Work Experience
Data Engineering Intern | IBM | Austin, TX | June 2024 – August 2024
● Assisted in building and maintaining ETL pipelines using Python and SQL to support business intelligence initiatives.
● Optimized data workflows, reducing report generation time by 15% through efficient query design.
● Collaborated with data scientists to integrate analytics into production systems, ensuring data quality.
Data Engineering Intern | Dell Technologies | Round Rock, TX | June 2023 – August 2023
● Supported the development of data pipelines using AWS Redshift and Apache NiFi, processing large volumes of customer data.
● Wrote Python scripts to automate data transformation tasks, saving 10 hours of manual work weekly.
● Contributed to cross-functional team efforts, aligning data solutions with business goals.
Languages
● English: Native
● Spanish: Basic
Resume Example #2 for Mid-level Data Engineer
Jackson Reed
Mid-level Data Engineer
Seattle, WA | (206) 555-1982 | jackson.reed@email.com
linkedin.com/in/jacksonreed | github.com/jreed-dev
Summary
Results-driven Data Engineer with 4+ years of experience crafting scalable data services and implementing efficient solutions for large-scale data processing. Skilled in AI powered pipelines, Azure Data tools, and cloud platforms like AWS and GCP. Passionate about enabling data analysis and driving decision-making by enhancing data quality, accuracy, and performance. Seeking to contribute to your career growth through innovative data science practices and enterprise-grade database management strategies.
Core Skills
Languages & Frameworks: Python, SQL, Scala, Java, Pandas, TensorFlow
Big Data & Streaming: Apache Spark, Kafka, Hadoop, Airflow, MapReduce
Cloud Platforms: AWS (Redshift, S3), Azure (Data Lake, Data Factory), GCP
Databases: PostgreSQL, MySQL, MongoDB, Cassandra, Snowflake
Data Tools & Services: Databricks, Power BI, Tableau, Docker, Git
Other: Data Modeling, ETL/ELT, API Integration, DevOps, Agile, Security
Professional Experience
Mid-Level Data Engineer
ShopNova Inc. – Seattle, WA
February 2022 – Present
● Developed end-to-end data pipelines for e-commerce analytics, integrating structured and raw datasets from multiple sources, including APIs and third-party platforms like Facebook Ads.
● Led the migration of legacy ETL workflows to Azure Data Factory, reducing data latency by 50% and enhancing data quality and reliability.
● Implemented data validation and cleansing techniques using Airflow and Pandas, improving data integrity and compliance with privacy policy requirements.
● Collaborated with stakeholders across engineering, product, and marketing to deliver insights from real-time user behavior analysis—resulting in a 12% boost in revenue from optimized targeting.
● Contributed to continuous improvement by mentoring junior engineers and publishing internal blog articles on best practices in data tools and AI-based analysis.
Associate Data Engineer
BrightEdge Analytics – San Jose, CA
June 2020 – January 2022
● Designed scalable data storage and processing pipelines using Apache Spark and Databricks, handling over 3 TB of data daily across distributed environments.
● Automated repetitive reporting tasks and monitoring using Python scripts and SQL jobs, saving 30+ hours monthly in manual labor.
● Improved data retrieval speed by 40% by optimizing complex joins in Redshift and refactoring existing schemas for better accessibility.
● Created operational dashboards in Tableau, visualizing key performance indicators (KPIs) for sales and support teams.
● Actively participated in weekly Agile ceremonies and helped streamline backlog grooming with clear task descriptions and delivery estimation.
Education
University of Illinois Urbana-Champaign
Bachelor of Science in Computer Science
Graduated: May 2020 | GPA: 3.7
Relevant Courses: Algorithms, Data Structures, Machine Learning, Big Data Systems
Capstone Project: Built an AI-based recommendation engine using collaborative filtering and Python, trained on large-scale datasets with 85% accuracy in predictive modeling.
Projects
Real-Time Inventory Optimization for Retail
Personal project – GitHub (github.com/jreed-dev/inventory-ai)
October 2023 – December 2023
● Developed a streaming system using Kafka and Spark to process IoT data from 500+ devices in retail outlets, improving stock replenishment speed by 30%.
● Stored data in Cassandra for fast read/write performance; integrated Power BI for real-time dashboarding.
● Modeled demand using TensorFlow and applied predictive analytics to forecast shortages and avoid downtime.
Certifications
● Microsoft Certified: Azure Data Engineer Associate (2023)
● Databricks Certified Data Engineer Associate (2022)
● Google Professional Data Engineer (2021)
Languages
● English – Native
● Spanish – Conversational
References
Available upon request. Also available: technical recommendation letters, sample projects, and GitHub contributions showing implementation of data science and AI-powered services
Final Tips for writing a Winning Data Engineer Resume
Here are some final tips to help you build a strong resume:
1. Proofread thoroughly before submitting. Typos, duplicates, and formatting errors can ruin your chances. Use tools like Grammarly, or ask a colleague to check your resume for errors.
2. Update your engineering resume regularly. Add new projects, accomplishments, and certifications. Your resume should reflect your current skills.
3. Seek feedback. Send a draft to a mentor, internship supervisor, or colleague. An outside perspective will help you identify weaknesses and improve your resume.
4. Track applications: Log submitted résumés and responses to analyze what works.
Land More Data Engineering Interviews. Fast.
Tired of your resume getting lost in the ATS black hole? Craft a standout, interview-winning resume in just 15 minutes – no formatting headaches.
Engineernow.com's builder is engineered for engineers:
● ATS-Optimized Templates: Built to sail through recruiter screens at FAANG and competitive tech firms.
● Data Engineering Skill Bank: Instantly showcase Python, SQL, Spark, AWS & other in-demand tech skills.
● Proven Career Tips: Get actionable advice on highlighting projects, metrics, and impact – what hiring managers crave.
● One-Click Export: Download polished PDF, DOCX, or DOC files ready to submit.
Conclusion
A successful data engineer resume balances technical expertise, measurable impact, and role-specific alignment. Whether you’re an entry-level candidate showcasing academic projects or a senior engineer demonstrating leadership in architecture decisions, the right resume can make your application stand out.
Stop struggling!
Start interviewing. Build Your Powerhouse Resume Now at Engineernow.com!
CREATE RESUME
Written by
Recent Posts

Pub: 23 Aug 2025 - Upd: 01 May 2026
9 min. read
Expat Job Scam Alert How to Avoid Fraud When Seeking Work Abroad