45 мин. чтения
Примеры резюме инженера по большим данным (Big Data) + подробный гайд 2026
Подаете вакансию на должность Big Data инженера в одну из ТОП IT-компаний или в быстрорастущий стартап? По статистике, на подобную позицию может быть одновременно более 800 претендентов на вакантное место. При таком количестве заявок на изучение одного резюме рекрутер тратит в среднем 7-15 секунд. Но 73% резюме даже не попадают в руки сотруднику отдела кадров, поскольку провалили первичную фильтрацию с помощью ATS. И только около 1% из общего количества попадают в шорт лист для более детального изучения.
На практике, у большинства кандидатов достаточно опыта и есть необходимые для должности навыки. Но при составлении резюме они совершают одинаковые ошибки: перечисляют технологии без контекста, не дают доказательств и не показывают, каких достигли результатов.
✔ Как составить сильное резюме для инженера по большим данным, которое привлечет внимание рекрутера?
✔ Как пройти первичное автоматическое сканирование и заставить систему ATS работать на вас?
✔ Как выделиться среди заявок других инженеров по большим данным и повысить шансы на собеседование, если у вас совсем нет опыта?
В этом гайде подробные стратегии составления резюме для Биг Дата инженера, а также наглядные примеры, которые показывают, как применять советы на практике.
Уже составили резюме, но нет уверенности, что все сделано правильно?
Получите мгновенную обратную связь с помощью Анализатора резюме от EngineerNow. Загрузите документ и добавьте описание вакансии — анализ и выдача оценки займет меньше минуты.
Система оценит:
✔ Адаптацию ATS и наличие ключевых слов
✔ Соответствует ли структура и форматирование ожиданиям HR-менеджеров
✔ Соответствие требованиям должности инженера по большим данным
✔ Убедительны ли формулировки
Узнайте, что работает, а что нет до того, как рекрутер увидит ваше резюме.
В этом обзоре:
- Подробная структура резюме инженера по большим данным с разбором каждого раздела;
- Стратегии адаптации для систем ATS — как написать резюме, чтобы ваша заявка не отсеялась на этапе первичного отбора;
- Особенности составления резюме в зависимости от опыта (джуниор, мидл, сеньор);
- Советы, как показать достижения, уровень подготовки и как правильно описать опыт, чтобы заинтересовать работодателя;
- Распространенные ошибки при составлении резюме.
Роль инженера по большим данным, аналитика рынка и ожидания работодателей
Инженер по большим данным (Big Data Engineer) — это специалист, который проектирует и поддерживает инфраструктуру для сбора, хранения и обработки колоссальных объёмов информации, измеряемых сотнями терабайт и даже петабайтами в сутки. На решениях Big Data построены рекомендательные алгоритмы Netflix, системы динамического ценообразования Uber и аналитические платформы Amazon.
Данные стали основой современной экономики. Они дают возможность аналитикам, маркетологам и топ-менеджерам понимать поведение аудитории, отслеживать интересы и строить более эффективные стратегии продвижения сервисов, услуг и товаров. Компании могут точнее сегментировать клиентов и предлагать именно то, что нужно. Поэтому спрос на специалистов, способных все это организовать, растёт взрывными темпами.
По данным LinkedIn и Glassdoor, количество вакансий Big Data Engineer увеличивается на 25–30% в год, а средняя зарплата в США в 2025 году превышает $150 тысяч. Компании активно инвестируют в облачные технологии, стриминговую обработку и искусственный интеллект, а значит, роль инженера по данным становится стратегически важной в цифровой трансформации.
Но в мире Big Data и потоковой обработки данных, задержки, краткосрочные сбои или погрешность в 2-3% может обернуться убытками в миллионы долларов. Поэтому работодатели тщательно подходят к отбору кандидатов на должность. В такой ситуации шаблонное резюме, которое просто перечисляет навыки и предыдущие должности, не имеет шансов выделиться.
Что хочет увидеть HR-менеджер в резюме кандидата на должность Big Data Engineer:
✔ Не просто знание стека инструментов для Big Data, но умение достигать конкретных результатов: строить пайплайны, которые собирают данные из нескольких источников, обеспечивать аналитику в режиме real-time и др.;
✔ Конкретные результаты работы и масштаб: сокращение времени формирования отчетов, увеличение точности аналитики, количество источников сбора информации, объем обрабатываемых данных;
✔ Влияние на бизнес: увеличение ROI, количества клиентов, продаж, сокращение расходов на рекламу (или наоборот, рост дохода от рекламы), экономия на облачную инфраструктуру, др.;
✔ Конкретные навыки и качества, которые зависят от структуры компании, конкретной должности (рядовой инженер или тим-лид), рабочих процессов. Это может быть умение находить нестандартные решения, способность работать в условиях ограниченного времени, навыки взаимодействия с финансистами, маркетологами, менеджментов и трансляции бизнес-требований в конкретные инструменты и др.
Необходимые навыки для Big Data инженеров
В работе инженер по данным использует десятки инструментов. Но в резюме не всегда уместно описывать полный список навыков. Если добавить нерелевантные технологии, легко размыть профиль, что станет причиной сомнений у рекрутера в глубине ваших знаний конкретного стека. Более того, в слишком большом списке легко запутаться и упустить важные навыки.
В повседневной работе инженер по данным использует десятки инструментов — от облачных платформ и систем потоковой обработки до фреймворков для оркестрации и аналитики. Но в резюме важно соблюдать баланс: показывать глубину, а не энциклопедию всего, что вы когда-либо пробовали.
Если перегрузить документ нерелевантными технологиями, профиль будет выглядеть размытым. У рекрутера может возникнуть сомнение: действительно ли вы эксперт в своём стеке или просто перечислили всё подряд? К тому же в слишком длинных списках легко потерять фокус и упустить самые важные навыки, которые важны для должности.
Совет. Составляя раздел с техническими навыками, сократите список до 10 наиболее релевантных. Для должности уровня senior список можно расширить до 15-20. Пишите только релевантные для должности и только если можете подтвердить глубокое знание стека цифрами и фактами.
Список технических навыков
Языки программирования:
● Python — основной язык для обработки данных, разработки ETL и автоматизации.
● Java — приложения корпоративного уровня и интеграция с экосистемой Hadoop.
● Scala — высокопроизводительные приложения Spark и функциональное программирование.
● SQL — сложные запросы, хранимые процедуры и оптимизация баз данных.
● R — статистический анализ и прототипирование моделей машинного обучения.
Технологии больших данных:
● Apache Spark — распределенные вычисления для пакетной и потоковой обработки.
● Экосистема Hadoop — HDFS, MapReduce, Hive, HBase для хранения больших объемов данных.
● Apache Kafka — потоковая передача данных в реальном времени и событийно-ориентированные архитектуры.
● Apache Airflow — оркестрация рабочих процессов и автоматизация пайплайнов.
● Apache Flink — обработка потоков с низкой задержкой для аналитики в реальном времени.
Облачные платформы:
● AWS — S3, EMR, Redshift, Lambda, Glue (озера данных, бессерверная обработка).
● Azure — Data Factory, Synapse, Databricks (интеграция на уровне предприятия, BI).
● GCP — BigQuery, Dataflow, Cloud Storage (машинное обучение, аналитика).
Базы данных и хранилища:
● Реляционные — PostgreSQL, MySQL, Oracle для транзакционных систем.
● NoSQL — MongoDB, Cassandra, DynamoDB для гибких схем проектирования.
● Хранилища данных — Redshift, Snowflake, BigQuery для аналитических задач.
● Поисковые системы — Elasticsearch для полнотекстового поиска и анализа логов.
Другие инструменты и технологии:
● Docker, Kubernetes — контейнеризация и оркестрация приложений для обеспечения масштабируемости и стабильности data pipelines.
● Git — система контроля версий, командная работа над проектами, CI/CD-практики.
● ETL-инструменты (Talend, Informatica) — проектирование и поддержка процессов извлечения, трансформации и загрузки данных из разнородных источников.
● BI-системы (Tableau, Power BI) — визуализация данных и построение интерактивных дашбордов для поддержки управленческих решений.
Совет: Не ограничивайтесь сухим списком технологий в разделе “Навыки” (Skills). Покажите свой технический бэкграунд в действии. Расскажите, как именно вы применяли инструменты и стек в реальных проектах — в разделе Experience или Projects.
Как продемонстрировать свои навыки в действии: не просто «Airflow, Spark, GCP», а «построил ETL-пайплайн на Airflow и Spark, сократив время загрузки данных в BigQuery на 40%».
Подкрепите это результатами в блоке Achievements и кратко подчеркните ключевую экспертизу в Summary. Такой подход делает профиль живым, убедительным и показывает, что за вашими навыками стоят реальные достижения.
Важные мягкие навыки
Инженерия данных — это не только про технологии. Инфраструктура для сбора и анализа данных создаётся не ради самих данных, а для людей — аналитиков, маркетологов, финансистов, специалистов по продажам и стратегическому планированию. Инженер по большим данным должен уметь решать конкретные бизнес-задачи с помощью стека Big Data технологий. Поэтому для успешного инженера по большим данным важно сочетание профессиональных и мягких навыков.
✔ Решение проблем и аналитическое мышление. Покажите способность разбирать сложные задачи, связанные с данными, на управляемые компоненты. Приведите примеры, когда вы находили узкие места в производительности или разрабатывали нестандартные решения, чтобы обойти технические ограничения.
✔ Коммуникация и сотрудничество. Проекты в области Big Data объединяют множество участников — инженеров, аналитиков, менеджеров, руководителей. Покажите, что вы умеете ясно объяснять технические концепции нетехнической аудитории и эффективно взаимодействовать с кросс-функциональными командами.
✔ Управление проектами. По мере роста масштабов и сложности задач ценность навыков управления проектами возрастает. Упомяните опыт работы по Agile, участие в планировании спринтов и управлении заинтересованными сторонами. Особенно важно для специалистов уровня senior и тимлидов.
✔ Непрерывное обучение. Сфера Big Data стремительно развивается — новые технологии и платформы появляются ежемесячно. Подчеркните своё стремление оставаться в тренде: расскажите о сертификатах, участии в конференциях, курсах или самостоятельных исследованиях.
Как формат выбрать для резюме инженера больших данных
Хронологический формат
По умолчанию, рекрутеры ожидают увидеть резюме в обратном хронологическом формате. Такое резюме строится вокруг вашего опыта: в нем подробно описывается карьерная история со списком обязанностей, задач и достижений для каждой должности. Дополнительно, для быстрого сканирования, инструменты и навыки выделяются списком в отдельном разделе.
✔ Главное достоинство хронологического формата: такое резюме показывает полученные навыки на практике, делает опыт осязаемым.

Резюме Big Data инженера, построенное вокруг опыта
Но обратный хронологический формат не настолько хорош для выпускников и начинающих инженеров — пробелы в опыте в таком резюме сразу бросаются в глаза. В таком случае больше подойдет функциональное резюме.
Функциональный формат резюме или резюме, основанное на навыках (skill-based resume)
Такое резюме строится вокруг навыков. Вместо простого списка, каждый навык подтверждается несколькими достижениями или примерами из реальных проектов. Опыт, наоборот, дается списком.
Достоинства функционального резюме:
✔ Смещает акцент с недостатка опыта на навыки и освоенные технологии.
✔ Позволяет подтвердить навыки на практике даже при отсутствии коммерческого опыта.
✔ Функциональное резюме получается более компактным и дает возможность уместить на одной странице разделы с достижениями, подробнее описать проекты, сместив внимание на то, чего уже вы достигли.
✔ В таком резюме легче продемонстрировать передаваемые навыки, полученные в другой индустрии (навыки программирования, работы с базами данных, личные качества и др.).
Функциональное резюме лучше всего подходит студентам, выпускникам, начинающим инженерам с опытом меньше года, а также специалистам, которые переходят в инженерию данных из смежных индустрий (веб-разработки, аналитики данных) или значительную часть карьеры провели на фрилансе.
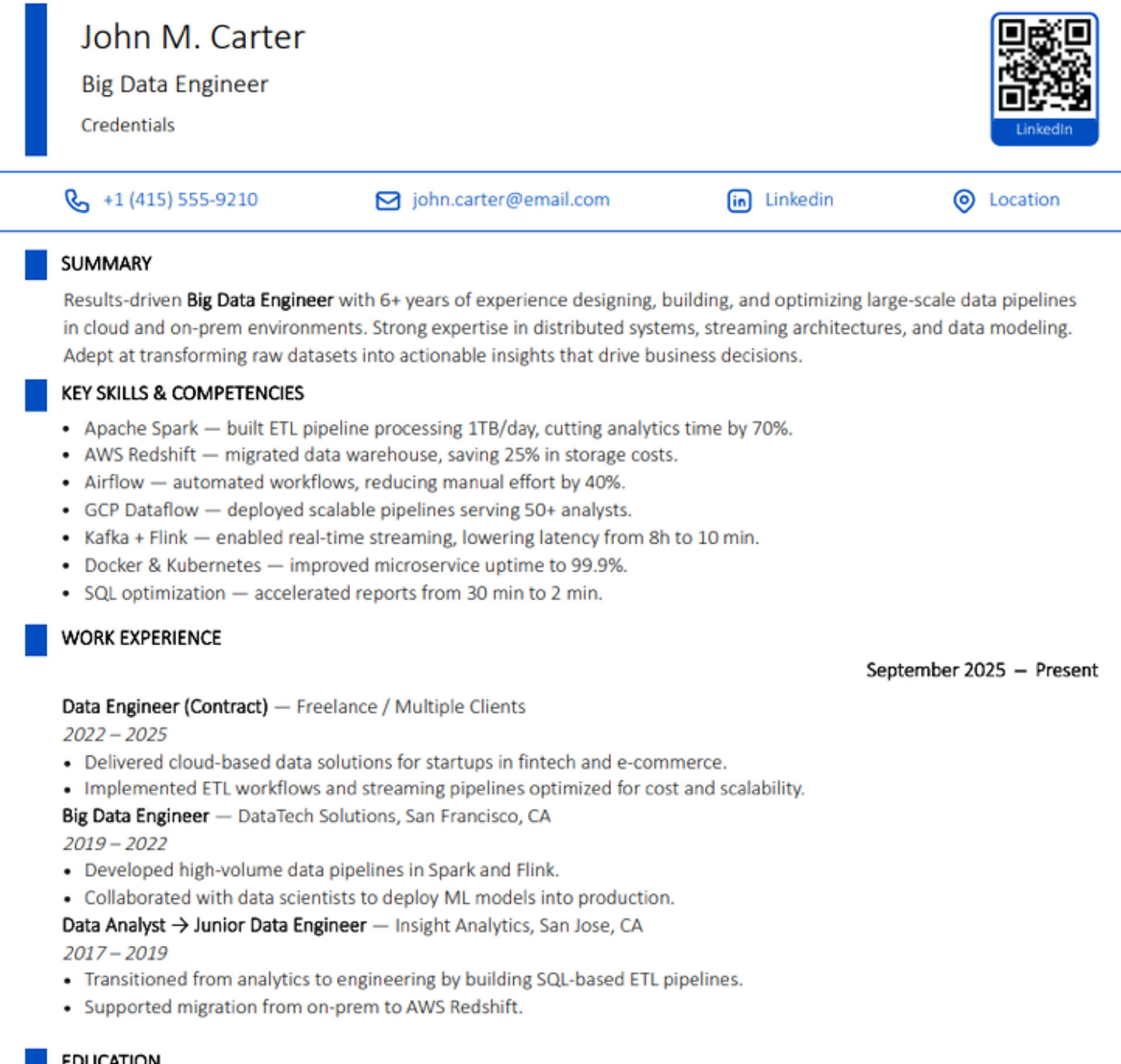
Пример функционального резюме для Big Data Engineer
Но выбирая этот формат, учитывайте недостатки функционального резюме:
- Рекрутеры могут ожидать резюме в хронологическом формате (если это не отбор кандидатов на стажировку).
- Если у навыков нет контекста, непонятно, какие задачи вы решали и как давно получен опыт, насколько знания актуальны.
При более детальном изучении рекрутер поймет, что коммерческого опыта у вас немного. А значит, важно быть убедительнее других кандидатов.
Гибридный формат
Этот формат объединяет лучшее из двух предыдущих: совмещает развернутое описание опыта и более подробное описание ключевых навыков. Альтернативный способ выделить навыки — показать наиболее значные результаты, которых удалось достичь с помощью конкретного стека, в разделе с достижениями или проектами.
Гибридный формат подходит:
✔ Выпускникам, если есть много значимых проектов и стажировок, были активно вовлечены в образовательный процесс, участвовали в волонтерской работе, занимались внеклассной работой и работали над личными проектами, ;
✔ Специалистам, которые переходят из смежной индустрии и с большим набором передаваемых навыков — позволяет показать насыщенную карьерную историю и при этом показать опыт с конкретным стеком;
✔ Специалистам со значимыми достижениями и глубоким владением конкретных инструментов и технологий.
Ключевые принципы для составления сильного резюме (Key Principles for Crafting a Strong Big Data Engineer Resume)
Как ведущий инженер, принимающий участие в найме, я пересмотрел тысячи резюме. И у многих соискателей была похожая проблема — шаблонные резюме. Почти все они выглядели одинаково: имя, фамилия, стандартные фразы о наличии опыта и почти идентичный список навыков и обязанностей. Ничего, что бы помогло выделиться, никаких доказательств, что специалист приносил пользу компании.
Хорошее резюме — это больше, чем красиво отформатированный лист бумаги со списком инструментов. Задача документа — показать, что вы лучший кандидат на конкретную позицию, продать ваши услуги на рынке труда. Как это сделать?
Есть три ключевых принципа:
№1 Акцентируйте внимание на результате, а не на обязанностях
Типичная ошибка — превращать резюме в список, в котором указаны одни должностные обязанности инженера по данным. Но цель любого бизнеса — не просто выполнять задачи, а получать результат: прибыль, эффективность, рост.
Вместо того чтобы писать «что я делал на работе», покажите «что я сделал для компании». Расскажите, как ваша работа помогла сократить расходы на инфраструктуру, ускорить аналитические процессы, повысить точность прогнозов или эффективность кампаний.
Big Data Engineer — это не оператор информационных систем, а инженер, который решает бизнес-проблемы с помощью данных и технологий. Резюме, в котором виден измеримый вклад — цифры, проценты, реальные улучшения — сразу выделяется на фоне остальных и значительно повышает шансы попасть на собеседование.
Совет! Избегайте слабых, обобщенных формулировок. Вместо них используйте сильные глаголы. Например:
❌ Не пишите: “работал с облачными сервисами AWS”;
✅ Скажите: "Разработал и внедрил AWS-конвейеры данных, увеличив скорость обработки на …%"
Такой подход показывает не просто, что вы знакомы с инструментом, но способны с его помощью решать конкретные задачи и достигать бизнес-целей.
№2 Добавляйте цифры, чтобы количественно оценить свою работу
Цифры — это универсальный язык, который превращает абстрактные заявления в конкретные, измеримые факты. Количественные показатели делают ваш опыт конкретным, и это лучший способ доказать вашу ценность для бизнеса.
Как превратить общие формулировки в сильные заявления с помощью цифр:
❌ Не пишите: “улучшил производительность”. Эта формулировка слабая: никаких доказательств, не понятно, какой эффект и стоил ли результат затраченных усилий;
✅ Скажите: “сократил время обработки данных на 73% — это позволило быстрее формировать портрет целевой аудитории и увеличить релевантность рекомендаций с 70% до 85%”. Понятный эффект, видно, как это сказалось на работе сервиса.
Добавляя цифры, вы не просто подтверждаете свой опыт, но и показываете, что вникли в суть бизнес-процессов и умеете решать задачи бизнеса.
Ключевые метрики, которые стоит показать в резюме (если они актуальны):
✔ эффективность: увеличение скорости запросов, сокращение времени формирования отчетов и др.;
✔ стоимость: сокращение затрат на инфраструктуру по обработке данных;
✔ производительность и масштаб: объем обрабатываемых данных, количество обрабатываемых запросов и прочее;
✔ надежность: снижение количества ошибок, увеличение времени доступности системы;
✔ вклад в команду: количество людей в подчинении, количество стажеров и др.
✔ влияние на бизнес: повышение точности моделей, улучшение точности таргетинга на целевую аудиторию, увеличение ROI рекламных кампаний.
Примеры сильных формулировок с количественными показателями:
● Масштаб обработки данных: «Создал пайплайн, обрабатывающий 5 ТБ данных ежедневно из 20 источников».
● Влияние на производительность: «Сократил время ответа на запрос с 30 секунд до 2 секунд».
● Экономия затрат: «Оптимизировал облачную инфраструктуру, что позволило сэкономить $500K в год».
● Вклад в команду: «Наставлял команду из 8 младших инженеров, улучшив качество кода на 25%».
№3 Адаптация резюме для должности и ATS
Типичная ошибка — отправлять общее резюме на все должности. Одно из условий сильного резюме Big Data Engineer — адаптация под конкретную вакансию. Почему это важно?
1. На первом этапе каждое резюме сканируется системой отслеживания соискателей (ATS). Она ищет в документе ключевые слова из описания вакансии. Если вы не используете точные термины, заявка, скорее всего, будет отклонена автоматически. Если резюме оптимизировано под ATS, оно будет одобрено системой.
2. У каждой компании свои процессы, цели, задачи, стек технологий. Благодаря адаптации резюме под конкретную вакансию, рекрутер сразу увидит ключевые навыки и опыт.
Как адаптировано резюме для вакансии и ATS:
✔ Добавляйте названия инструментов и технологий не только в список навыков, но и в другие разделы: с опытом, проектами, достижениями, Summary.
✔ Описывайте наиболее актуальные для должности задачи, проекты и достижения.
✔ В разделе с образованием сделайте фокус на курсах, практических занятиях и проектах, актуальных для должности.
✔ Перепишите раздел Саммари под конкретную вакансию.
Примеры резюме биг дата инженера для разных специализаций
Пример резюме инженера по большим данным №1 - Big Data / ML Engineer
Иван Петров
Big Data / ML Engineer
Телефон: +7 (916) 123-45-67 | Email: ivan.petrov@example.com | Москва, РФ
Summary
Senior Big Data / ML Engineer с 6+ годами опыта разработки дата-пайплайнов и внедрения моделей машинного обучения. Применял Spark, Kafka и TensorFlow для построения предиктивных систем, что повысило точность прогнозов продаж на 15 %. Уверенный пользователь облачных warehousing решений в AWS и GCP.
Навыки
● ML & Data Science: scikit-learn, TensorFlow, PyTorch
● Big Data Frameworks: Apache Spark, Kafka, Flink
● Облачные платформы: AWS (Redshift, S3, EMR), GCP (BigQuery, Dataflow)
● Языки программирования: Python, Scala, SQL
● Базы данных: PostgreSQL, MongoDB, Cassandra
● Контейнеризация и оркестрация: Docker, Kubernetes
● Методологии: Agile, Scrum
● Техническая документация, problem solving, внимательность к деталям
Опыт работы
ML / Big Data Engineer
Яндекс / Москва, РФ | 2021–настоящее время
● Спроектировал и внедрил scalable пайплайн на Spark + Kafka, ускорив обработку данных с 24 до 4 часов
● Разработал модель прогнозирования оттока клиентов (TensorFlow), что снизило отток на 12 %
● Интегрировал ML-решения в BI-дашборды и документировал инженерную документацию
● Вёл code review и наставлял junior-разработчиков
● Оптимизировал хранение данных, сократив затраты на S3 / Redshift на 20 %
Big Data Engineer
Сбер / Москва, РФ | 2018–2021
● Внедрил потоковую обработку транзакционных данных в реальном времени (Kafka + Flink)
● Автоматизировал процесс загрузки данных в облачное хранилище (ETL пайплайн)
● Настроил мониторинг и контроль качества данных с алертами
● Составлял эксплуатационные инструкции и сопровождал техническое обслуживание систем
● Участвовал в проекте оптимизации рекламных кампаний, повысив ROI на 18 %
Образование
Бакалавр по направлению Информационные системы и технологии, 2014–2018
Московский государственный технический университет имени Баумана, факультет «Информатика и вычислительная техника»
Сертификаты
● AWS Certified Machine Learning – Specialty
● Сертификат «Data Engineering with Google Cloud»
Конференции
● Спикер конференции BigDataRU 2023, доклад «Ускорение ML-пайплайнов»
Иностранные языки
● Английский язык: Upper-Intermediate
Образец резюме инженера по большим данным №2 - Streaming / Real-Time Data Engineer
Алексей Смирнов
Big Data Engineer - Streaming / Real-Time
+7 (901) 543-21-09 | aleksey.smirnov@example.com | Казань, РФ
Summary
Real-Time Data Engineer с 5 годами опыта работы в стриминговых сервисах и обработке событий. Разработал систему потоковой аналитики с Kafka Streams и Flink, что сократило задержки потоковой обработки данных до 200 мс. Опыт построения архитектуры распределённых систем и их эксплуатации.
Навыки
● Streaming & Real-Time: Kafka Streams, Flink, Kinesis
● Big Data Frameworks: Spark, Hadoop
● Облачные решения: AWS (Kinesis, Lambda), Google Cloud Platform
● Языки: Java, Python, SQL
● Базы данных: Cassandra, ClickHouse, PostgreSQL
● Контейнеризация: Docker, Kubernetes
● Agile, инженерная документация, problem solving
Опыт работы
Streaming Data Engineer
Spotify / Лондон, UK (удалённо) | 2021–настоящее время
● Проектировал и развернул real-time pipeline на Kafka + Flink для визуализации вовлечённости пользователей
● Оптимизировал пропускную способность потоков с 10 000 до 50 000 сообщений/с
● Внедрил систему мониторинга и алертинга для потоков
● Документировал принципы работы и операционные процедуры инженерных систем
● Встраивал real-time сигналы в ML-модели для персонализации треков
Real-Time Engineer / Data Engineer
Яндекс Музыка / Москва, РФ | 2018–2021
● Внедрил стриминг логов прослушиваний, обеспечив свежие данные в течение 1 минуты
● Построил ETL-процессы для анализа пользовательского поведения
● Внедрил контроль конфиденциальности и политику безопасности обработки данных
● Поддерживал эксплуатацию инфраструктуры и централизованное логирование
Образование
Казанский федеральный университет, факультет информационных технологий
Специальность: Информационные системы и технологии, 2013–2017
Сертификаты
● «Apache Kafka Developer»
Конференции
Спикер конференции Strata Data 2022 — доклад «Low-latency pipelines»
Иностранные языки
Английский — Advanced, Немецкий — Intermediate
Soft skills:
● Коммуникабельность
● Навыки работы в команде
● Опыт наставничества (Mentoring)
● Контроль качества
Ваше резюме — первый шаг к карьерному успеху, но одного описания карьерной истории со списком навыков недостаточно. В этом видео вы узнаете, как составить убедительное сопроводительное письмо, которое покажет, почему именно ваш опыт идеально подходит под требования вакансии.
Освойте этот подход — и ваше резюме перестанет быть просто перечнем проектов, а станет сильной профессиональной историей, которая привлечёт внимание рекрутера и повысит шансы получить приглашение на интервью.
Как создать резюме инженера по данным: руководство по структуре и описанию разделов
Какую информацию включить в резюме? Универсального шаблона нет, вы можете адаптировать структуру под свой опыт, проекты и достижения. Однако есть два важных критерия, которых стоит учесть:
1. Читаемость для HR-менеджера. На изучение профиля кандидата уходит не больше 7–10 секунд, поэтому важно, чтобы ключевые данные — опыт, навыки, достижения — были на виду и специалист по найму смог сразу их найти.
2. Соответствие требованиям вакансии и ATS. Прежде чем резюме попадёт в руки человека, его проверяет система отслеживания кандидатов (ATS). Она ищет ключевые слова и формулировки, чтобы определить, подходит ли кандидат под требования.
Что это значит? Важно убедиться, что HR-менеджер сможет быстро найти необходимую информацию, а ПО корректно ее считает. Поэтому придерживайтесь стандартной структуры, которая соответствует “ожиданиям” и рекрутера, и “машины”.
Универсальная структура: к ней привыкли HR-менеджеры, на нее настроены ATS:
Обязательные разделы резюме Big Data Engineer
● Header (Шапка с контактами) — имя, специальность, контакты, ссылки на LinkedIn, GitHub или портфолио, город проживания.
● Summary / Professional Objective — вступительный абзац из 2–5 предложений о вашем уровне, опыте и ключевых технологиях.
● Навыки (Core Skills) — список инструментов и технологий, сгруппированных по категориям (Big Data, облака, языки программирования, базы данных).
● Опыт (Experience) — профессиональный опыт с акцентом на достижения и метрики (формула «задача → действие → результат»).
● Образование (Education) — университет, степень, специальность.
Дополнительные разделы (усилят вашу заявку, если они релевантны)
● Сертификаты (Certifications) — AWS, GCP, Databricks, Cloudera и другие.
● Проекты (Projects) — значимые проекты (open-source, pet-projects, хакатоны).
● Мягкие навыки (Soft Skills) — умение работать в команде, тайм-менеджмент, аналитическое мышление, другие личные качества
● Публикации и Конференции (Publications & Conferences) — статьи, доклады на митапах или конференциях.
● Иностранные языки (Languages) — если вы претендуете на международные роли, укажите знание иностранных языков.
● Награды и достижения (Awards & Achievements) — профессиональные награды или внутренние признания в компании.
● Другая информация — если актуально, можно указать доп. данные: желаемый график работы, наличие водительских прав, желаемая зарплата.
💡 Совет: если вы только начинаете карьеру в Big Data, дополнительные разделы (проекты, сертификации, курсы) помогут компенсировать недостаток опыта и выделиться среди других кандидатов.
Контактная информация
Что нужно добавить в раздел с контактами:
- ФИО;
- Название должности, специализация
- Номер телефона;
- Адрес электронной почты — должен выглядеть профессионально;
- Ссылка на профили LinkedIn (если нет, составьте и заполните профиль — обязательно для заявок в США, Канаде, ЕС);
- Ссылки на проекты на GitHUB или портфолио (если доступно);
- Локация (опционально — пишите только если это указано в описании вакансии).
Проследите, чтобы этот раздел был лаконичным, хорошо читался и выглядел профессионально. Кажется, все просто. Но даже здесь некоторые кандидаты делают ошибки, что автоматически ставит крест на заявке.
Типичные ошибки, которых стоит избегать в разделе резюме с контактами:
❌ Креативные шрифты — выглядят непрофессионально, сложно читаются;
❌ Вместо имени указан псевдоним — он может вызвать подозрения, делает резюме непрофессиональным;
❌ неформальный адрес email формата kittycat@..., macho97@... — увидев такой адрес почты, рекрутер моет подумать, что вы несерьезно относитесь к работе;
❌ Дополнительная информация: дата рождения, количество детей, точный адрес, семейное положение, другая личная информация — это не нужно, может вызвать у рекрутера удивление.
Как должен выглядит раздел с контактами:
Николай Петров
Инженер по большим данным
+1 889 12 34 567 |nicpetrow.dataengineer@mail.com |linkedin.com/in/nicpetrow.dataeng
Профессиональное резюме (Summary) vs. Цель (Objective)
Выбор между этими двумя разделами зависит от вашего опыта.
Профессиональное резюме (Summary)
Summary — это краткий вступительный абзац из 3–5 предложений, который подытоживает карьерную историю, ключевые навыки и достижения. Это своего рода визитная карточка, по которой рекрутер решает, стоит ли подробнее изучать ваш профиль.
Такой формат подходит специалистам с опытом: он позволяет сразу подчеркнуть сильные стороны и показать релевантность позиции.
Цель Summary — мгновенно убедить рекрутера, что вы подходите под вакансию, ещё до прочтения остального текста. Укажите здесь самое важное: количество лет опыта, основные технологии, которыми вы владеете, и конкретные измеримые результаты вашей работы.
При составлении Саммари придерживайтесь принципов сильного резюме:
- Фокус на достижениях, а не на обязанностях. Покажите, что вы не просто выполняли задачи, а приносили конкретные результаты.;
- Используйте цифры, чтобы показать результаты работы и влияние на бизнес: “ускорили загрузку данных на 30%”, “сократили расходы на инфраструктуру на 15%”;
- Адаптируйте под вакансию. Добавляйте ключевые слова из описания должности, выделяйте проекты, наиболее близкие к требованиям работодателя.
Сравните сильное и слабое Summary
❌ Слабое Summary
“Опытный инженер, знаком с технологиями больших данных. Работал с базами данных и ETL. Ищу возможности для развития и применения своих навыков.”
✅ Сильное Summary
“Senior Big Data Engineer с 7+ годами опыта в проектировании масштабируемых дата-пайплайнов на AWS и Spark. Эксперт в потоковой обработке данных с Kafka и Flink, оптимизировал процессы, сократив время обработки с 12 часов до 30 минут. Успешно создавал облачные решения, обрабатывающие более 100 млн событий пользователей ежедневно.”
Разница очевидна:
Слабое summary = общие фразы, размытое описание: нет уровня, стека технологий, достижений и метрик. Такое summary «потеряется» среди сотен других.
✔ Формула сильного summary = конкретика + технологии + результаты. Цифры и конкретные достижения подтверждают опыт и цепляют внимание рекрутера.
Пример сильного и слабого Summary на английском языке
❌ Week Summary
“Experienced engineer with knowledge of big data technologies. Worked with databases and ETL. Looking for opportunities to grow and apply my skills.”
✅ Strong Summary
“Senior Big Data Engineer with 7+ years of experience designing large-scale data pipelines on AWS and Spark. Expert in real-time streaming with Kafka and Flink, optimizing workflows that reduced data processing time from 12h to 30min. Proven track record of building cloud-native solutions supporting 100M+ user events daily.”
Цель карьеры (Objective):
Короткое вступление на два — три предложения, сфокусированное на ваших карьерных стремлениях. Этот формат подходит для начинающих специалистов, недавних выпускников или тех, кто меняет сферу деятельности. Карьерная цель — хороший способ показать энтузиазм, готовность учиться, вникать в процессы компании. Впрочем, сюда можно добавить и значимые достижения, достигнутые во время стажировок или обучения в университете.
Как составить сильный раздел с “Карьерной целью”? Покажите, что у вас уже есть базовые навыки и опыт, а также готовность прикладывать усилия, чтобы раскрыть свой потенциал.
Сравните:
❌ Слабая карьерная цель
“Хочу работать инженером по большим данным и развиваться в этой сфере.”
Описание слишком общее: не указан стек, непонятно, есть ли навыки работы с пайплайнами, не ясно, какие перспективы у такого специалиста.
✅ Сильная карьерная цель
“Более 3 лет опыта в разработке дата-пайплайнов на Spark, Kafka и AWS для создания масштабируемых real-time решений, повышающих эффективность бизнес-аналитики. Стремлюсь глубже вникать в бизнес-процессы, быстро осваивать новые инструменты и вносить вклад в развитие компании, ориентированной на инновации.”
Такое описание выглядит живым и стратегическим: есть конкретика по опыту, ключевые технологии, акцент на мышлении, развитии и том, какую ценность специалист принесет компании в перспективе.
Слабая и сильная карьерная цель на английском
❌ Weak Career Objective
“Looking for a job as a Big Data Engineer where I can use my skills and grow in my career.”
✅ Strong Career Objective
“To leverage 5+ years of experience in building data pipelines with Spark, Kafka, and AWS to design scalable real-time data solutions that drive business insights and efficiency. Eager to deepen expertise in business processes, quickly master new tools, and contribute to a company that values innovation and continuous growth.”
Профессиональные навыки
Указывайте актуальные и релевантные навыки. Если вы освоили большой список технологий, сократите его до 10–15 ключевых для вакансии (тимлиды и сеньоры могут указать до 20).
Как правильно указать правильные навыки?
Для резюме в обратном хронологическом формате
Укажите навыки списком, без дополнительного описания. Группируйте по категориям, чтобы рекрутер смог сразу увидеть нужный стек.
Пример раздела Skills в резюме в хронологическом формате:
● Big Data Frameworks: Apache (Spark, Kafka, Airflow)
● Облачные платформы и хранилища: AWS (S3, Redshift), Google Cloud Platform (BigQuery, Dataflow)
● Языки программирования: Python, SQL, C++
● Базы данных: MySQL, PostgreSQL, MongoDB
● Инструменты и технологии: Kubernetes, Git, Power BI
● Методологии: Agile, Scrum
Показывайте навыки на практике.
Просто перечислить инструменты недостаточно — HR хочет видеть, как именно вы их применяли:
✔ Включайте технологии в описание опыта и проектов: покажите, как использование Docker или Spark помогло оптимизировать пайплайны или улучшить масштабируемость.
✔ Связывайте инструменты с конкретными бизнес-задачами и метриками, чтобы показать умение приносить пользу компании. Например, «создал в Tableau интерактивный дашборд для отдела продаж, сокративший время формирования отчетов на 30%».
Навыки в функциональном резюме Big Data Engineer
Функциональный формат делает акцент не на хронологии работы, а на ключевых навыках и конкретных примерах их применения. Такой подход особенно полезен, когда::
- опыт разнородный, и вы хотите выделить конкретные компетенции;
- есть проекты, фриланс или стажировки вместо «длинного» стажа;
- важно подчеркнуть владение определёнными инструментами и технологиями.
В функциональном резюме опыт обычно даётся списком, без детальных объяснений. Поэтому доказательства вашего умения использовать инструменты и решать с их помощью реальные задачи нужно размещать в разделе с техническими навыками.
Как заполнять раздел с навыками в функциональном резюме
1. Выберите 3–5 ключевых технологий или групп навыков (например, ETL-пайплайны, облачные хранилища, контейнеризация, визуализация).
2. Рядом с каждой группой укажите 1–2 основных инструмента.
3. Под каждой группой приведите 1–3 конкретных кейса применения и достигнутого результата.
При описании кейсов, покажите инструмент и эффект.
Формула сильного пункта:
Что сделал (технология/группа) + инструмент или стек + какой результат
Такой подход делает раздел навыков конкретным, убедительным и легко читаемым для рекрутера и ATS.
Как составить раздел с опытом для функционального резюме инженера по большим данным — пример:
Оптимизация дата-пайплайнов (Spark & Kafka)
● Разработал и внедрил real-time пайплайны на базе Apache Spark Streaming и Kafka, сократив задержку загрузки данных с 5 минут до 30 секунд.
● Интегрировал пайплайны в кластер Kubernetes, обеспечив автоматическое масштабирование и отказоустойчивость.
Облачная инфраструктура и контейнеризация
● Перенёс ETL-процессы в AWS EMR с использованием Docker, что снизило затраты на инфраструктуру на 20%.
● Автоматизировал деплой через Git + CI/CD, ускорив релизы продакшн-решений.
Бизнес-аналитика и визуализация данных
● Создал интерактивные дашборды в Tableau и Power BI для мониторинга KPI отдела продаж и маркетинга.
● Преобразовал сложные массивы данных в бизнес-инсайты, что позволило увеличить ROI маркетинговых кампаний на 15%.
ETL и интеграция данных
● Реализовал процессы извлечения и загрузки в Talend и Informatica, объединив данные из ERP и CRM-систем в единое хранилище.
● Повысил качество данных на 25% благодаря внедрению правил трансформации и валидации.
Образец резюме инженера по большим данным — пример раздела с проектами на английском языке
Data Pipeline Optimization with Spark & Kafka
● Designed and deployed real-time data pipelines using Apache Spark Streaming and Kafka, reducing data ingestion latency from 5 minutes to under 30 seconds.
● Integrated pipelines into a Kubernetes cluster for automatic scaling and fault tolerance.
Cloud Infrastructure & Containerization
● Migrated ETL processes to AWS EMR with Dockerized components, cutting infrastructure costs by 20%.
● Automated deployment workflows via Git + CI/CD, ensuring faster delivery of production-ready data solutions.
Business Intelligence & Data Visualization
● Built interactive dashboards in Tableau and Power BI to monitor key KPIs for sales and marketing teams.
● Translated complex datasets into actionable insights, enabling a 15% increase in campaign ROI.
ETL Development & Data Integration
● Implemented ETL processes with Talend and Informatica, consolidating data from multiple ERP and CRM systems into a unified data warehouse.
● Improved data quality by 25% through validation and transformation rules
Раздел «Опыт работы»
Структура и размер раздела зависят от формата резюме:
● Функциональный формат: опыт работы указывается списком предыдущих должностей с названием компании и периодом работы. Но основной акцент делается на раздел с навыками и обучением, где показываются реальные достижения и освоенный стек технологий.
● Хронологический формат: раздел Опыт работы — самый важный, на него смотрят технические руководители и HR сразу после Summary и Навыков.
Что указывать в разделе с опытом хронологического резюме Big Data инженера
- название компании и период работы;
- занимаемая должность;
- список из 3-5 пунктов, где описаны должностные обязанности и достижения, проекты, результаты.
Описывайте предыдущие должности в обратном хронологическом порядке — самую последнюю позицию указывайте первой. Если вы долго работали в одной компании, каждое повышение лучше описать отдельно — это подчеркнёт карьерный рост.
Совет. Если большая часть опыта — одна должность без повышения или фриланс, стоит использовать функциональный или гибридный формат, чтобы сместить акцент на достижения и освоенный стек технологий.
Как написать раздел с опытом, который привлечен внимание HR-менеджера
1. Фокус на достижениях, а не на обязанностях. Опишите, какие задачи вы решили и как ваша работа повлияла на компанию.
2. Используйте сильные глаголы. Вместо «работал с пайплайнами» пишите: разработал, построил, оптимизировал, интегрировал, внедрил, обучил, наставил.
3. Добавляйте количественные показатели. Цифры, сравнения, масштабы делают вклад осязаемым.
4.Указывайте контекст. Покажите проблему, использованные инструменты и технологии, а также для кого предназначалось решение (аналитиков, маркетологов, топ-менеджеров).
Сильные и слабые формулировки для раздела “Опыт”
❌ “Работал с AWS-системами” →
✅ “Разработал и внедрил AWS-конвейеры данных, увеличив скорость обработки на 30%.”
❌ Поддерживал конвейеры данных →
✅ “Оптимизировал ETL-процессы, сократив время их выполнения на 73% и повысив надежность до 99.9%”
❌ Сотрудничал с членами команды →
✅ “Руководил кросс-функциональной командой по интеграции моделей машинного обучения в конвейер данных, что повысило точность прогнозной аналитики на 25%”
❌ “Ответственен за обработку больших объемов данных” →
✅ “Руководил разработкой масштабируемой платформы, обрабатывающей более 100 ТБ данных ежедневно, что повысило возможности анализа данных”
❌ “Обеспечивал целостность данных” →
✅ “Мигрировал более 5 ТБ данных из локальных систем в облако AWS, обеспечив 99.9% целостности и безопасности данных.”
❌ “Участвовал в проектах по машинному обучению” →
✅ “Разработал инструменты для анализа и суммирования данных о сбоях, что позволило внедрить модели машинного обучения, повысив точность прогнозирования на 20%.”
Формулы SAR и STAR для описания опыта
Лучший способ дать контекст, показать навыки на практике и продемонстрировать влияние на бизнес — формулы SAR и STAR.
1. Формула SAR (Situation – Action – Result)
● S (Situation) — в какой ситуации вы работали, с какой проблемой или задачей столкнулись.
● A (Action) — что конкретно сделали, какие инструменты использовали.
● R (Result) — какой результат получили, желательно в цифрах.
Пример для Big Data Engineer:
«Разработал пайплайн обработки данных (Action) для маркетингового отдела, столкнувшегося с задержкой отчетности на 24 часа (Situation). В результате время генерации отчетов сократилось до 30 минут (Result).»
2. Формула STAR (Situation – Task – Action – Result)
STAR более детализированная версия SAR:
● S (Situation) — контекст, проблема.
● T (Task) — ваша роль, конкретная цель.
● A (Action) — что сделали, какие инструменты применили.
● R (Result) — измеримый результат, эффект для бизнеса.
Пример:
«Компания испытывала сложности с хранением больших объемов логов (Situation). Мне было поручено спроектировать масштабируемое решение (Task). Внедрил хранилище данных на AWS S3 с использованием Spark для предварительной обработки (Action), что позволило сократить затраты на хранение на 40%, ускорил доступ к данным для аналитиков (Result).»
💡Совет:
✔ Используйте STAR, если хотите подробно раскрыть задачу и показать контекст. Актуально, если проектов и задач не много, но нужно показать свой бекграунд и понимание бизнес-процессов.
✔ Используйте SAR, если нужен компактный и емкий формат для резюме.
Всегда добавляйте глаголы действия и цифры: объем данных, время, экономию, рост метрик.
Образование
Для специалистов уровня middle и senior
Раздел образование не так ценен как опыт. HR-менеджеру достаточно убедиться, что у вас есть необходимый диплом. Предпочтительнее высшее техническое образование по направлению: информационные технологии, компьютерные науки, программная инженерия.
Укажите:
● степень и название (бакалавр, магистр, PhD);
● учебное заведение, год выпуска.
Если есть значимые достижения (награды, победы в олимпиадах или хакатонах, патенты), можно указать, чтобы подчеркнуть уровень подготовки.
Для джунов, стажеров и выпускников без опыта
Образование — это важный раздел, который позволяет показать уровень подготовки и наличие практических навыков.
Что указать в разделе “Образование” начинающему биг дата инженеру:
● Степень (бакалавр, магистр, PhD) и специальность;
● Название колледжа/университета, год выпуска;
● Укажите средний балл, если он выше 3,5 для США, ЕС и больше 4,0 для РФ, Беларуси, Казахстана, Украины, стран СНГ;
● Ключевые курсы или проекты (Machine Learning, Distributed Systems, Cloud Computing);
● Название выпускного проекта и курсовых работ, если они связаны с должностью;
● Релевантные внеклассные проекты, связаны с вакансией.
При описании проектов, курсовых или лабораторных работ, расскажите, какие инструменты использовали и каких результатов достигли. Используйте сильные слова, добавляйте цифры.
А вот такая информация как форма обучения, факультет, не нужна.
Пример описания раздела Образование
Бакалавр компьютерных наук, 2023
Национальный исследовательский университет «Высшая школа экономики» — Москва, Россия
● Ключевые курсы: Алгоритмы и структуры данных, Распределённые системы, Управление базами данных, Облачные вычисления, Машинное обучение
● Выпускная работа: Проектирование и реализация real-time пайплайна данных с использованием Apache Kafka и Spark
● Учебный проект: Разработал прототип хранилища данных с интеграцией более чем из 5 источников, обеспечив BI-отчётность в Tableau
Пример описания Образования на английском языке
Bachelor of Science in Computer Science, 2023
National Research University Higher School of Economics — Moscow, Russia
● Key Courses: Data Structures & Algorithms, Distributed Systems, Database Management, Cloud Computing, Machine Learning
● Thesis: Design and Implementation of a Real-Time Data Pipeline with Apache Kafka and Spark
● Academic Project: Developed a data warehouse prototype integrating data from 5+ sources, enabling BI reporting in Tableau
Проекты — опциональный раздел, который поможет продемонстрировать знания на практике
Если вы начинающий специалист или переходите в сферу Data Engineering из другой области, добавьте раздел «Проекты». Это отличная возможность закрыть вопрос о недостатке опыта в конкретной индустрии и показать свои знания на практике.
Что стоит указать в разделе инженерных проектов по обработки данных:
● Тип проекта: учебный, личный или pet-project.
● Роль: что именно делали вы (например: спроектировал архитектуру, настроил пайплайн, оптимизировал ETL).
● Технологии: перечислите инструменты и стек (Spark, Kafka, Airflow, AWS, Docker, Tableau и др.).
● Результат: измеримые показатели или ценность (сократил время обработки, улучшил визуализацию, создал масштабируемое решение).
При описании проектов используйте 3 принципа сильного резюме.
Real-Time Data Pipeline Project
● Построил потоковый пайплайн на базе Kafka + Spark Streaming для обработки данных из социальных сетей в реальном времени.
● Развернул решение в AWS с использованием Docker и Airflow для оркестрации задач.
● Результат: сократил задержку обработки данных с 10 минут до 45 секунд, обеспечив возможность real-time аналитики.
Сертификаты
Согласно анализу рынка, около 60% вакансий инженера данных упоминают наличие сертификатов. Для начинающих специалистов курс повышения квалификации помогает компенсировать недостаток опыта. Для опытных — подтвердить актуальность навыков и глубину знаний современных технологий.
Укажите сертификаты списком с указанием года сертификации. Добавляйте только актуальные для должности сертификаты за последние 5 лет.
Самые ценные сертификаты для Big Data Engineer в 2025:
● AWS Certified Data Analytics – Specialty
● Google Cloud Professional Data Engineer
● Databricks Certified Data Engineer
● Snowflake SnowPro
Особенности составления резюме в зависимости от уровня опыта
Главная ошибка в резюме — приукрасить действительность. Попытка обмана рано или поздно будет раскрыта. Говорите правду, ведь независимо от уровня опыта, вы можете заинтересовать работодателя. Главное, это показать ваши сильные стороны в зависимости от того, на какой ступени вы находитесь. Для начинающего инженера это история о потенциале и фундаменте, для специалиста среднего уровня — история о росте и результатах, а для старшего — история о лидерстве и стратегическом влиянии.
Junior / Entry-Level Data Engineer
На старте карьеры основной акцент — потенциал, готовность учиться и прочный теоретический фундамент.
● Ключевые разделы: образование (с сильными оценками), стажировки, учебные и личные проекты, сертификаты, подтверждающие интерес к Big Data.
● Покажите, что вы умеете применять технологии на практике даже в мини-проектах.
● Язык резюме: «глубокие знания принципов» («Knowledge of»), «практический опыт…» («Experience with») — акцент на знакомстве с инструментами.
● Оптимальная длина: 1 страница.
● Чего избегать: длинные списки технологий без практического опыта и нерелевантные проекты.
Mid-Level Data Engineer
На этом уровне важно показать рост и доказать способность самостоятельно решать сложные задачи с измеримыми результатами.
● Главный акцент — опыт работы: достижения через конкретные метрики и результаты.
● Важны проекты, участие в кросс-функциональных командах и работа в продакшн-среде.
● Язык описания: сильные глаголы действия — “внедрил” (implemented), “оптимизировал” (optimized), “разработал” (developed) — подчеркивающие активную роль и ценность для бизнеса.
● Длина резюме: обычно 1 страница, но уже насыщенное содержанием.
● Главная ошибка: описание обязанностей вместо достижений и отсутствие количественных показателей, таких как скорость, масштаб, экономия.
Senior / Lead Data Engineer
Для сеньоров резюме должно рассказывать историю лидерства, стратегического мышления и влияния на ключевые бизнес-показатели.
● Важно подчеркнуть архитектурные решения, наставничество (менторство) команды, внедрение масштабных инициатив.
● Основные разделы: опыт работы (с акцентом на стратегические проекты и результаты), лидерские навыки, управление проектами.
● Язык описания: формулировки высокого уровня ответственности — спроектировал (Architected), вел команду, руководил (Led), наставлял (Mentored).
● Длина резюме: 1–2 страницы, особенно если нужно показать разнообразие крупных проектов.
● Ошибки: упор на базовые задачи или перечисление технологий без контекста; отсутствие акцента на лидерстве и стратегическом вкладе ослабляет резюме.
Как превратить свой опыт в сильные истории для резюме и собеседований
Эффективное резюме инженера по данным открывает возможности, но именно умение грамотно рассказать о своём опыте делает вас по-настоящему конкурентоспособным кандидатом.
Метод STAR (Ситуация — Задача — Действие — Результат) — это проверенная во всём мире формула, помогающая ясно и убедительно представить свои достижения.
Посмотрите видеоруководство и узнайте, как с помощью метода STAR превратить сухие пункты резюме в яркие профессиональные истории, которые привлекут внимание рекрутера и помогут уверенно пройти собеседование.
Примеры резюме Big Data Инженера по уровню квалификации и опыту
Образец резюме инженера по большим данным в функциональном формате №1 - Junior Big Data Engineer
Александр Новиков
Junior Big Data Engineer
Москва, Россия
+7 (915) 123-45-67 | a.novikov.data@email.com | linkedin.com/in/alexandernovikovde | github.com/novikov-data
Цель карьеры
Начинающий инженер по большим данным с сильной академической базой и практическим опытом разработки ETL-пайплайнов на Python и SQL. Стремлюсь применять знания в области алгоритмов и распределенных систем для решения бизнес-задач в команде, где ценятся понимание процессов и готовность к непрерывному обучению. Ищу возможность внести вклад в проекты, требующие аналитического подхода.
Технические навыки
● Языки программирования: Python, SQL, Java (базовый)
● Big Data фреймворки: Apache Spark (PySpark), Apache Airflow
● Базы данных: PostgreSQL, MongoDB
● Облачные платформы: AWS (S3, EC2), Yandex Cloud
● Инструменты: Git, Docker, Linux
● Мягкие навыки: Решение проблем, отличные коммуникативные навыки, работа в команде
Проекты
● Анализ оттока клиентов телеком-компании (Учебный проект)
○ Разработал ETL-пайплайн на Python и PySpark для обработки 10 ГБ данных.
○ Провел количественный анализ и визуализировал ключевые метрики, выявив 3 основные причины оттока.
○ Стек: Python, Pandas, PySpark, Jupyter Notebook, Matplotlib.
● Real-time пайплайн для агрегации логов (Pet-project)
○ Настроил конвейер с использованием Apache Kafka и Spark Streaming для обработки потоковых данных.
○ Развернул кластер в Docker; обеспечил высокую доступность сервиса.
○ Стек: Apache Kafka, Docker, Apache Spark.
Образование
Бакалавр прикладной математики и информатики
Национальный исследовательский университет «Высшая школа экономики» (НИУ ВШЭ), Москва
2021 – 2025 (ожидаемая дата окончания)
● Средний балл: 4.7
● Курсовой проект: «Оптимизация алгоритмов обработки графов в Apache Spark».
Сертификаты
● «Big Data Essentials: HDFS, MapReduce and Spark RDD» (Coursera, 2024)
● «AWS Cloud Practitioner Essentials» (Coursera, 2023)
Пример резюме инженера по большим данным №2 - Mid-Level
Мария Иванова
Big Data Engineer - Retail Analytics
+7 (495) 234-56-78 | maria.ivanova@example.ru | Санкт-Петербург
Summary
Data Engineer с таргетом на ритейл и автоматизацию аналитики. 4 года опыта построения ETL / ELT пайплайнов и data warehousing проектов для розничных сетей. В X5 Group участвовала в проекте оптимизации цепочек поставок, снизив затраты на логистику на 10 %.
Навыки
● ETL / ELT: Airflow, dbt, Apache NiFi
● Big Data Frameworks: Spark, Kafka
● Облачные хранилища: AWS Redshift, Snowflake
● Языки: Python, SQL
● Базы данных: MySQL, PostgreSQL, Aurora
● BI / визуализация: Power BI, Tableau
● Контейнеризация: Docker, Kubernetes
● Agile, problem solving, коммуникация
Опыт работы
Data Engineer (Retail Analytics)
X5 Group / Москва, РФ | 2022–настоящее время
● Построила ETL-конвейер для интеграции продаж, запасов и логистики из 5 регионов
● Создала интерактивный дашборд в Power BI, который позволил сократить время подготовки отчётов на 30 %
● Оптимизировала SQL-запросы, ускорив отчёты до 50 %
● Вела техническую документацию и обеспечивала контроль качества данных
● Сотрудничала с бизнес-аналитиками и маркетологами для внедрения инсайтов
Junior Data Engineer
ООО «Розничные решения» / Санкт-Петербург | 2020–2022
● Реализовала автоматизированный pipeline обработки данных о скидках и акциях
● Настроила загрузку данных в хранилище, документировала архитектуру
● Участвовала в сопровождении систем, контроле эксплуатации
Образование
Магистр по направлению Компьютерные науки
Санкт-Петербургский государственный университет,
Факультет «Прикладная математика и информатика», 2016–2020
Дополнительно / Проекты
● Сертификат «Google Cloud Data Engineer»
Проекты:
«Прогнозирование товарных дефицитов»
● построен ML-модуль, снижение затрат по складам на 8 %
Языки
Русский — Родной; Английский — Upper-Intermediate
Мягкие навыки (Soft skills)
● Коммуникабельность;
● Внимание к деталям
● Готовность к командировкам
Образец резюме Big Data инженера №2 - Senior Level
Мария Соколова
Senior Big Data Engineer
Санкт-Петербург, Россия
+7 (911) 987-65-43 | m.sokolova.lead@email.com | linkedin.com/in/mariyasokolovade | github.com/sokolova-de
Профессиональное резюме
Старший инженер по большим данным с 8-летним опытом архитектуры и развертывания высоконагруженных сервисов обработки данных. Эксперт в области реализации отказоустойчивых решений на AWS и Apache Spark. Доказанный опыт руководства командами до 10 человек, успешного выполнения проектов в срок и в рамках бюджета. Нацелен на внедрение передовых практик для повышения эффективности и снижения затрат.
Ключевые навыки
● Программирование: Python, Scala, SQL
● Big Data & Очереди: Apache Spark, Apache Kafka, Apache Flink, Apache Airflow
● Облака & DevOps: AWS (EMR, S3, Redshift, Glue, Lambda), Docker, Kubernetes, Terraform
● Базы данных & Хранилища: Snowflake, PostgreSQL, Cassandra, Elasticsearch
● Управление: Agile/Scrum, управление проектами, наставничество, ведение кросс-функциональных команд
Опыт работы
Ведущий инженер по большим данным | ООО «Тинькофф Технологии», Москва
Июнь 2020 – настоящее время
● Разработал и внедрил новую архитектуру data lake на AWS, объединившую данные из 50+ источников и обрабатывающую 15+ ТБ данных ежедневно.
● Руководил командой из 8 инженеров; внедрил процессы код-ревью и CI/CD, что повысило надежность выпусков на 40%.
● Оптимизировал затраты на облачную инфраструктуру на 25% (экономия ~$300K/год) за счет автоматизации управления ресурсами и перехода на Spot инстансы.
● Обеспечил соблюдение политик безопасности и конфиденциальности данных (GDPR) во всех сервисах.
Инженер по большим данным | Яндекс, Москва
Август 2017 – Май 2020
● Построил высоконагруженный ETL-пайплайн на Apache Spark и Airflow для обработки данных поисковых запросов, сократив время выполнения задач с 6 до 1.5 часов.
● Реализовал систему мониторинга и оповещения, повысившую uptime сервисов до 99.95%.
● Активно участвовал в найме и наставничестве новых сотрудников.
Образование
Магистр компьютерных наук
Санкт-Петербургский политехнический университет Петра Великого (СПбПУ), Санкт-Петербург
2015 – 2017
Бакалавр информатики и вычислительной техники
Санкт-Петербургский политехнический университет Петра Великого (СПбПУ), Санкт-Петербург
2011 – 2015
Сертификаты
● AWS Certified Solutions Architect – Professional (2023)
● Databricks Certified Data Engineer Professional (2022)
Принципы визуального дизайна и форматирования
Профессиональное резюме — это баланс между визуальной привлекательностью и удобством чтения. Хороший дизайн не отвлекает, а помогает рекрутеру быстро найти ключевую информацию.
Принципы дизайна
✔ Типографика: используйте профессиональные, легко читаемые шрифты (Calibri, Arial, Helvetica) размером 10–12 pt.
✔ Поля и интервалы: сохраняйте широкие поля (в идеале - 2 - 2,5 см) и интервалы между разделами для легкого восприятия.
✔ Структура и иерархия: используйте единое форматирование для заголовков, подзаголовков и основного текста.
✔ Объем: 1 страница для джуниров, 1-2 страниц — для опытных специалистов.
✔ Цвет: используйте минимальные цветовые акценты, если они есть, сохраняя высокую контрастность для удобства чтения.
Технические детали оформления резюме инженера по данным
✔ Формат файла: сохраняйте документ в PDF (если не указан RTF, Microsoft Word - docx) с понятным названием: Имя-Фамилия-Data-Engineer-Resume.pdf
✔ ATS-оптимизация: используйте стандартные заголовки (Summary, Skills, Experience и др.), избегайте таблиц и графиков. Добавляйте ключевые слова из описания вакансии в разные разделы.
✔ Корректура: проверьте грамматику, даты, названия компаний и контакты — даже мелкие ошибки создают впечатление невнимательности.
Ваши следующие шаги к сильному резюме
Создание резюме инженера по данным, которое выделит вас среди других кандидатов — это стратегическая работа над вашей профессиональной историей. Вы показываете не просто техническую экспертизу, а умение достигать целей бизнеса и приносить результат.
Принципы сильного резюме:
● Фокус на достижениях и измеримом бизнес-эффекте, а не на списке инструментов.
● Адаптация под каждую вакансию.
● Отражение прогресса и роста в карьере.
● Баланс между технической глубиной и бизнес-контекстом.
Грамотно составленное резюме открывает двери и приносит приглашение на собеседование, а ваши навыки — приводят к успеху. Создайте документ, который расскажет вашу историю убедительно и профессионально.
Готовы сделать следующий шаг?
Попробуйте EngineerNow.org — конструктор резюме, созданный специально для инженеров. Получите мгновенную экспертную обратную связь через наш анализатор резюме или ускорьте карьерный рост с помощью курса «Инженер-миллионер».
Ваша следующая успешная роль начинается с резюме, которое работает на вас.

Written by
Недавние Посты

Опуб: 04 июн. 2025 - Обно: 01 мая 2026
6 мин. чтения
$10,000 инженером в Саудовской Аравии, Катаре, Кувейте, ОАЭ! ГАЙД КАК ЭТО СДЕЛАТЬ!
Опуб: 12 февр. 2025 - Обно: 01 мая 2026
7 мин. чтения
5 вопросов на собеседовании Инженера и как на них нужно отвечать

Опуб: 25 апр. 2025 - Обно: 01 мая 2026
7 мин. чтения
Следует ли вам получить степень магистра или доктора в области инженерии?