54 min. read
Big Data Engineer Resume Examples (2026) + Complete Writing Guide
Thinking about applying for a Big Data Engineer role at a FAANG company or a fast-growing startup? Here’s the reality check: in a top tier company, you’ll likely be competing against 800+ applicants for the same position. So, with that kind of volume, recruiters typically spend only 7–15 seconds reviewing a single resume.
Here’s the kicker: 73% of resumes never even reach a recruiter’s desk because they fail the initial ATS screening. Out of the hundreds submitted, only around 1% make it to the shortlist for a serious review.
The hard truth? Most candidates do have the right technical skills needed for the role and solid experience. But where they fall short is in how they present that experience in their resumes. They make the same mistakes over and over: dumping a long list of tools without context, skipping measurable results, or failing to show how their work actually moved the needle for the business.
This guide shows you how to avoid those mistakes and gives you the tools to win:
✔ Craft a standout Big Data Engineer resume that grabs recruiters’ attention in seconds
✔ Beat the ATS and make it work for you
✔ Stand out and land interviews—even if you’re early in your career
Inside, you’ll find proven strategies, strong real-world examples, and ready-to-use templates to help you build a resume that gets interviews.
Not Sure Your Resume Makes the Cut?
Get instant feedback with EngineerNow's Resume Analyzer. Simply upload your resume and paste the job description—results in under a minute.
Our resume checker evaluates:
✔ ATS compatibility and keyword optimization
✔ Achievement impact and quantification
✔ Structure, formatting, and readability
✔ Alignment with Big Data Engineer job requirements
See exactly what's working and what needs improvement—before recruiters do.
Here’s what you’ll get inside this guide:
● A clear, step-by-step structure of a Big Data Engineer resume—with pro tips for each section.
● Smart ways to optimize for ATS while keeping your resume easy for humans to read.
● Role-specific writing strategies for junior, mid-level, and senior Big Data Engineers.
● Practical methods to showcase achievements, technical expertise, and measurable impact.
● The most common mistakes that kill resumes—and how to avoid them.
● Effective techniques for tailoring your application to match specific job postings and stand out in crowded applicant pools.
The Role of a Big Data Engineer: Market Trends & Employer Expectations
Big Data Engineers design and maintain the systems that process data at massive scale—hundreds of terabytes or even petabytes every day. They're the force behind Netflix's recommendations, Uber's dynamic pricing, Amazon's analytics platforms.
Data has become the backbone of modern business. It drives everything from product strategy to marketing campaigns. That's why demand for Big Data Engineers is surging—Glassdoor reports 25-30% annual job growth, with average U.S. salaries exceeding $150K in 2025. Companies across several industries are pouring billions into cloud infrastructure, real-time analytics, and AI—making data engineers absolutely critical to digital transformation.
But here's the reality: in Big Data, even a 2-3% accuracy error—or a short delay in real-time analytics—can cost millions. That's why employers are incredibly selective when hiring. A cookie-cutter resume that simply lists skills and previous positions won't cut it. According to recent research, hiring managers receive hundreds of applications for each open position, making it tough to stand out without a strategic approach.
What hiring managers want to see in your Big Data Engineer resume:
✔ Proof you can turn tools into results—like building scalable data pipelines, enabling real-time dashboards, or cutting query runtimes by 40%.
✔ Measurable outcomes: faster reporting cycles, improved accuracy, cost savings.
✔ Clear business impact: boosted ROI, customer growth, increased sales, reduced cloud costs, or higher ad revenue.
✔ Role-specific strengths: whether as an individual contributor or team lead, employers want problem-solving, cross-team collaboration, and the ability to translate business needs into technical solutions.
Pro tip from recruiters: “A Big Data Engineer’s resume should tell a story of impact—not just list technologies. Show how you saved money, improved performance, or scaled a system. That’s what gets you shortlisted. The right approach speaks volumes about your understanding of the role.”
Essential Skills for Big Data Engineer Resume
Big Data Engineers run operations involving dozens of tools in their day-to-day job. But when it comes to your resume, less is more. Listing every technology you've ever touched isn't just overwhelming — it can actually hurt your chances. Recruiters may wonder whether you have real depth in the stack that matters most. Plus, long unfiltered lists make it easy to bury the important skills under irrelevant ones.
Pro tip: Keep your technical skills section focused. Aim for around 10–15 core skills that are most relevant to the role. For senior-level candidates, you can extend the list to about 20, but only if every single one is directly tied to the job description. This approach ensures clarity and helps you manage the reader's attention effectively.
Core Hard Skills for Big Data Engineer Resume
Programming Languages
● Python – The go-to for ETL, automation, large-scale data processing.
● Java – Enterprise-level apps and Hadoop ecosystem integration.
● Scala – High-performance Spark applications and functional programming.
● SQL – Advanced queries, stored procedures, and database optimization.
● R – Statistical analysis and machine learning prototyping.
Big Data Frameworks
● Apache Spark – Distributed computing for batch and stream processing.
● Hadoop Ecosystem – HDFS, MapReduce, Hive, HBase for large-scale storage and processing.
● Apache Kafka – Real-time event streaming and data pipelines.
● Apache Airflow – Workflow orchestration and automation.
● Apache Flink – Low-latency stream processing for real-time analytics.
● Apache NiFi – Data flow automation and real-time data ingestion.
Cloud Platforms
● AWS – S3, EMR, Redshift, Lambda, Glue (data lakes, serverless, analytics).
● Azure – Data Factory, Synapse, Databricks (enterprise integration, BI).
● GCP – BigQuery, Dataflow, Cloud Storage (scalable analytics, ML).
Databases & Storage
● Relational – PostgreSQL, MySQL, Oracle (transactional systems).
● NoSQL databases – MongoDB, Cassandra, DynamoDB (flexible schemas).
● Data Warehousing – Redshift, Snowflake, BigQuery (analytical workloads).
● Search Engines – Elasticsearch (full-text search, log analytics).
Other Tools
● Docker & Kubernetes – Containerization and orchestration for scalable pipelines.
● Git – Version control, collaboration, CI/CD practices.
● ETL Tools – Talend, Informatica for enterprise-grade data pipelines.
● BI Tools – Tableau, Power BI for dashboards and data visualization.
👉 Don’t just drop professional skills in a list—show them in action. In your Experience and Projects sections, highlight how you used Spark to cut reporting time in half, or how your Kafka pipeline enabled real-time customer analytics. Otherwise, these become mere jargon without context. That's what makes the difference between “buzzwords” and “proof.”
Soft Skills That Set Big Data Engineers Apart
Big Data isn’t just about frameworks and pipelines. You’re building systems that real people depend on—analysts, marketers, executives, even finance teams. That's why hiring managers look for engineers who can pair technical expertise with strong soft skills. In today's collaborative work environment, technical know-how alone isn't enough.
✔ Problem-Solving & Analytical Thinking. Show how you break down complex data challenges, identify bottlenecks, and design elegant solutions. Resume example: “Debugged Spark performance bottlenecks, cutting runtime by 25%”— Recruiters love seeing measurable problem-solving like this. This displays your ability to tackle tough issues head-on.
✔ Communication & Collaboration. Data projects involve multiple stakeholders across businesses. Prove you can translate technical concepts for business audiences and work effectively across teams. Resume example: “Explained Kafka pipelines to non-technical stakeholders in marketing, aligning data delivery with campaign timelines”. The way you convey complex ideas to others demonstrates your value beyond coding.
✔ Project Management. Organizational skills become crucial as you target senior or lead roles. Highlight experience leading Agile sprints and coordinating with cross-functional teams. Mention any small wins in managing timelines or resources that resulted in successful project delivery.
✔ Continuous Learning. The Big Data landscape evolves constantly, with new tools and methodologies emerging regularly. Staying ahead means pursuing certifications, attending conferences, taking online courses, and working on side projects that keep your skills sharp in a fast-moving field. This attitude of lifelong learning is something employers actively seek.
Recruiter insight: “The best resumes strike a balance—they prove you can handle the tools and that you understand the business value behind them. Candidates who speak the language of both technology and business outcomes are the ones who receive callbacks.”
Data Engineer Resume Format Selection: Matching Structure to Experience
Your format choice shapes how recruiters interpret your background. Choose strategically based on your experience profile.
Reverse-Chronological Format (Most Common)
Recruiters expect to see a resume for data engineer in reverse-chronological format by default. It highlights your career progression through detailed work history, showing responsibilities, tasks, and measurable achievements for each role. Professional skills are typically listed in a separate, organized section.
Best for: Experienced Big Data Engineers with solid work history who can demonstrate value through past roles and quantifiable impact.
Advantage: Makes your expertise tangible and credible by showing real-world application of skills in production environments. Hiring managers can quickly connect your technical stack with proven results.

⚠️ Watch out: This format isn’t ideal for new graduates, early-career engineers, or career changers. With limited experience, employment gaps or unrelated roles stand out. In such cases, consider a functional or hybrid resume instead.
Functional (Skills-Based) Resume
If you're a recent graduate or breaking into data engineering from another field, a traditional chronological resume may highlight gaps rather than strengths. That's where the functional resume comes in.
Instead of focusing on job titles, this format revolves around core technical competencies. Each key skill is supported by specific examples—whether from academic projects, internships, freelancing, or personal initiatives. Work history is still included but in a condensed form, often at the end.
Key advantages:
✔ Resume format shifts focus from limited experience to technical skills and problem-solving abilities.
✔ Validates expertise through concrete achievements, even without full-time industry experience.
✔ Creates space for detailed Projects section.
✔ Perfect for showcasing transferable skills (e.g., programming, databases, problem-solving) from related fields
Best for:
● Recent grads with strong academic projects but under a year of professional experience
● Career changers from software development, analytics, or BI roles
● Freelancers with diverse but non-linear project backgrounds
⚠️ Important considerations:
● Many recruiters still prefer chronological resume for experienced Big Data engineers
● Skills may feel “out of context” without specific work environments
● Your limited commercial experience will become apparent—so your projects and achievements need to be exceptionally compelling
Hybrid (Combination) Resume Format
A hybrid resume blends the strengths of both chronological and functional formats. It typically starts with a focused skills or key achievements section, followed by a detailed work history in reverse chronological order. This allows you to spotlight critical technologies and accomplishments upfront while still showing career progression.
Combination resume best for:
● Mid-level Big Data engineers advancing toward senior roles with specialized expertise
● Career changers, entering data engineer with solid transferable experience
● Professionals with strong project portfolios and steady employment history
Key advantage: Hybrid resume is flexible and recruiter-friendly. It balances a clear career history with the opportunity to highlight specialized skills (e.g., Kafka streaming, Snowflake modeling, Spark optimization) or projects that prove measurable technical impact.
⚠️ Watch out: This format can quickly become cluttered if not structured well. Avoid duplicating the same details in both the skills and experience sections. Keep achievements concise and make sure each section adds unique value.
Recruiter insight: “Hybrid resume works well when candidates have specific technical depth but want to show career stability. Just don't make me hunt for the same information twice.”
Core Principles for Best Data Engineer Resume
After reviewing thousands of engineering resumes in hiring roles, I've seen the same pattern: most data engineers look nearly identical. Generic templates with technical skills lists and job descriptions that could apply to anyone. Nothing that set the candidate apart. It's a common mistake many professionals make, and it puts you at a disadvantage in a crowded job market.
The reality: most resumes fail because they focus on what you did instead of what you achieved. Recruiters want to see impact, not just responsibilities. This is the key difference between someone who merely lists their duties and someone who clearly demonstrates value.
Your resume isn't just a job application—it's your value proposition. Think of it as a conversation starter that speaks directly to hiring managers about what you bring to the table.
Your goal: Prove you're not just another engineer who knows Spark and Kafka—you're the engineer who optimized the data pipeline and saved the company 40% in processing costs. That's the picture you need to paint for readers scanning your resume in those critical first seconds.
Here are the three core principles that separate winning resumes from the pile:
1. Lead With Outcomes, Not Just Tasks
The most common mistake? Listing only what you were “responsible for” without outcomes. Companies don't care about your task list—they care about your results: cutting infrastructure costs, boosting processing efficiency, or improving data delivery speed. This is the wrong approach, and it's easier to fix than you might think.
Remember! A Big Data Engineer isn't just maintaining infrastructure—you're solving business problems. Each line on your resume should affirm this point.
Shift your mindset from “What did I do?” to “What impact did I create?” Show the value you bring. That's what captures an employer's attention and makes them want to hear more about your career story.
Pro Tip! Replace weak, generic statements with strong, results-driven language. Ask yourself: does this line shine a light on my contributions, or does it merely describe daily tasks?
Resume example:
❌ Weak: “Worked with AWS cloud services”
✅ Strong: “Designed and implemented AWS data pipelines that reduced processing time by 40% and cut infrastructure costs by $200K annually”
See the difference? The first could describe anyone on the team. The second proves measurable business impact that directly affects the company's bottom line and puts your achievement front and center.
2. Add Numbers to Quantify Your Work
Numbers transform abstract claims into credible proof points. They make your contributions measurable, instantly understandable and memorable. This quantitative approach remains one of the most effective ways to capture attention.
How to turn generic statements into powerful claims with numbers? Don't just say what you improved — show by how much. This small change in how you present information makes a great difference.
❌ Weak: “Improved performance”
✅ Strong: “Reduced data processing time by 73%, enabling faster audience profiling and increasing recommendation relevance from 70% to 85%.”
The first is weak: no proof, unclear what effect was achieved or if results justified the effort. The second proves technical skill and business value, giving readers a clear picture of your impact.
Key areas to quantify (when relevant):
● Performance: query speed improvements, processing time reductions
● Scale: data volumes handled, sources integrated, concurrent users supported
● Efficiency: cost savings, resource optimization, automation gains
● Quality: error rate reductions, uptime improvements, accuracy increases
● Business impact: revenue increase, customer growth, operational improvements
● Leadership: team size mentored, processes improved, knowledge sharing sessions conducted
Examples of strong, quantified statements:
● “Built ETL pipeline processing 5 TB daily from 20+ diverse data sources”
● “Optimized query performance from 30 seconds to sub-2-second response times”
● “Led infrastructure migration that saved $500K annually in cloud costs”
● “Mentored 8 junior engineers, improving team code quality by 25%”
The key: Numbers don't just confirm your experience—they prove you understand how to drive business results. This level of detail is what makes you memorable to hiring managers who review hundreds of applications.
3. Tailor Your Resume for the Role & ATS
Sending the same generic resume to every job is another common mistake. A strong Big Data Engineer resume is customized for each posting — and here’s why it matters:
1. Almost all tech companies use an Applicant Tracking System (ATS) that scans for exact keywords from the job description. Miss them, and your resume may never reach a recruiter.
2. Customizing your data engineer resume, you showcase not just your experience, but that you understand the role, its tech stack, and the company’s priorities. Recruiters immediately see your interest and the key skills needed for the role.
How to tailor your resume for your next data engineer positions:
✔Mirror key tools & technologies from the job description — e.g., AWS, GCP, Spark, Kafka, dbt. Include specific keywords not only in your skills list, but throughout experience, projects, achievements, and your summary.
✔ Highlight the most relevant projects & achievements — ETL pipelines, data processing optimizations, cloud migrations, or infrastructure improvements.
✔ Adjust your resume summary to reflect the job description’s focus and language, showing immediate relevance.
✔ Emphasize education & certifications that align with the role’s technology stack.
A tailored resume signals relevance instantly and dramatically improves your chances of passing the first ATS screening — demonstrating a precise fit for the role, not just general experience.
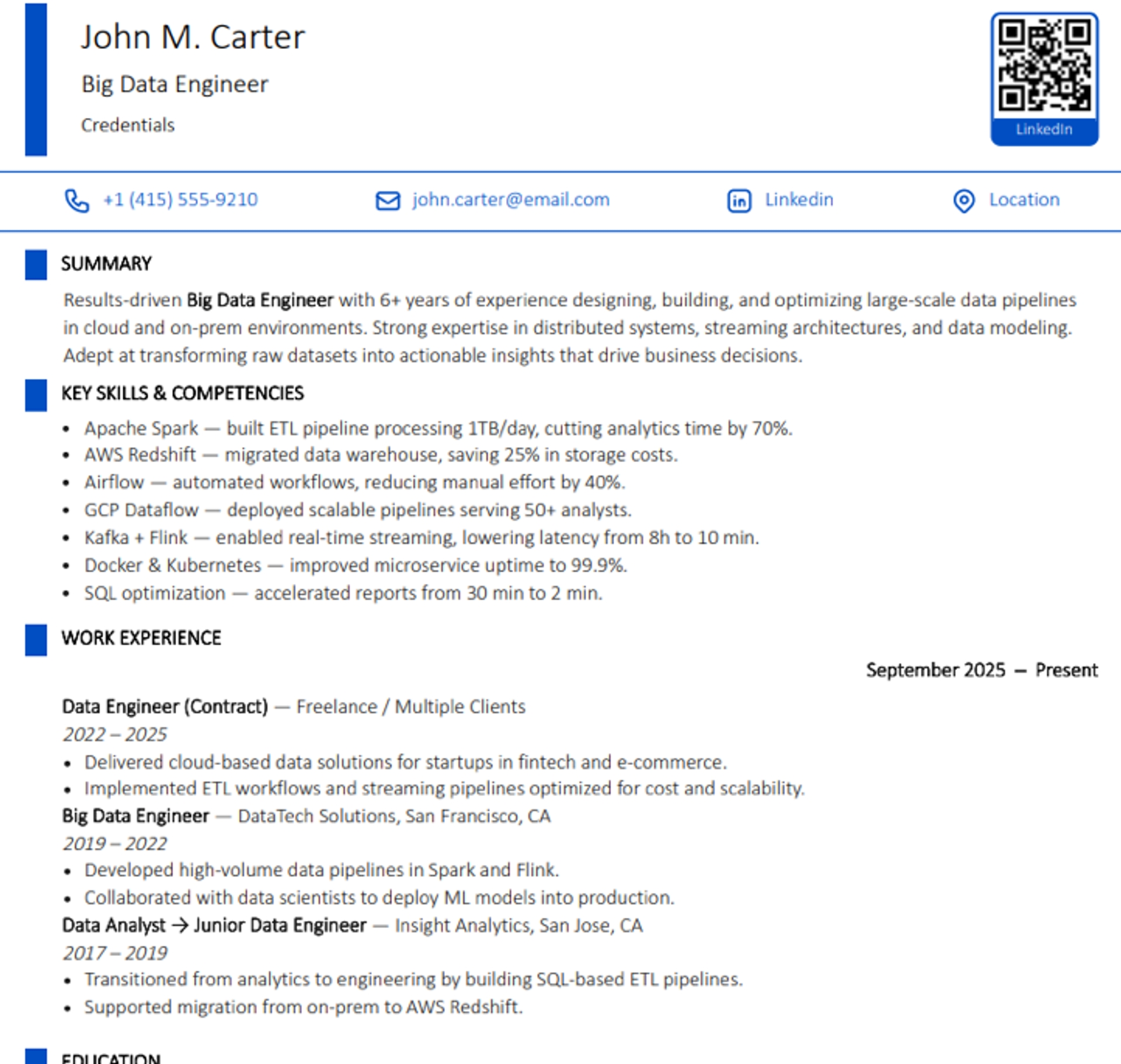
Big Data Engineer Resume Examples Tailored for The Data Engineering Roles
Big Data Engineer Resume Sample #1 — Machine Learning (ML) Focus
Markus Schneider
Senior Big Data Engineer (ML Specialization)
markusschneider-de@gmail.com | +89 898 893 34 34 | Berlin, Germany
LinkedIn: linkedin.com/in/markusschneider-de
GitHub: github.com/mschneiderML
Summary
Senior Big Data Engineer with 8+ years building scalable ML pipelines and data ingestion workflows from scratch. Have experience integrating disparate sources using Spark, cleaned data to feed ML models, and migrated from Oracle to cloud platforms. Proven record enabling faster model training and more efficient data delivery. Strong communication skills with data scientists and analysts, ensuring business intelligence outcomes match requirements.
Technical Skills
● Big Data: Apache Spark, Hadoop, Airflow
● ML Pipelines: TensorFlow Extended (TFX), MLflow
● Cloud: GCP BigQuery, AWS S3/EMR, Vertex AI
● Databases: PostgreSQL, Oracle
● Tools: Docker, Kubernetes, Git, Tableau
Experience
Senior Data Engineer | Zalando SE, Berlin | 2020–Present
● Built ML-ready data lake from scratch on GCP, consolidating 30+ sources using Spark. Resulting ingestion capacity boosted model training speed by 40%.
● Migrated 12 TB of legacy data from Oracle into BigQuery with zero downtime, improving overall querying performance.
● Cleaned data pipelines feeding personalization models; reduced prediction errors by 22%.
● Interacted with data scientists to align features upon business terms, ensuring efficient data availability for 25+ production ML models.
Data Engineer | IBM Germany | 2016–2020
● Designed custom ETL workflows supporting NLP-based chatbots, processing 500K+ daily requests.
● Optimized Spark jobs, reducing runtime from 6h to 50m.
● Created BI dashboards in Tableau, enabling executives to access actionable statistics faster.
Education
Master’s Degree. Computer Science | Technical University of Munich | 2015
Big Data Engineer Resume Sample #2 — Retail / Business Intelligence Focus
Claire Thompson
Big Data Engineer (Retail & BI)
Toronto, Canada | clairethompson-BDE@mail.com | +1 803 123 45 786 linkedin.com/in/clairethompson-ca | github.com/clairedata
Summary
Big Data Engineer with 6+ years in retail analytics, driving business intelligence solutions that reduce costs and boost revenue. Skilled in creating efficient data ingestion pipelines, migration from Oracle, and developing BI dashboards that provide more efficient reporting. Known for strong communication with stakeholders and ability to turn data info into actionable insights. Microsoft certified Azure Data Engineer Associate.
Technical Skills
● Big Data: Spark, Kafka, Flink, Hive
● BI: Looker, Power BI, Tableau
● Cloud: AWS (Redshift, Glue, S3), Azure Synapse
● Databases: Oracle, MySQL, Snowflake
● Tools: Docker, Airflow, Git
Experience
Big Data Engineer | Shopify, Toronto | 2020–Present
● Architected BI platform handling 5 TB+ retail data daily from 25 disparate sources using Spark; improved reporting accuracy by 30%.
● Migrated sales data from Oracle to Snowflake, enabling better querying performance and cutting infrastructure costs by 25%.
● Cleaned data and implemented schema mapping which reduced BI reporting errors by 40%.
● Created customer segmentation models with BI dashboards, resulting in 18% uplift in targeted sales campaigns.
Data Engineer | Hudson’s Bay Company, Toronto | 2017–2020
● Built ETL processes from scratch, ingesting POS and e-commerce data into AWS Redshift.
● Interacted with analysts and managers to ensure layout of dashboards matched retail KPIs.
● Automated data ingestion flows with Airflow, reducing manual efforts by 70%.
Education
B.Sc. Data Science | University of Toronto | 2017
Certifications
● AWS Certified Data Analytics – Specialty
● Microsoft Azure Data Engineer Associate
Languages
English — native; Spanish — fluent
Big Data Engineer Resume Sample #3 — Real-Time Streaming Platforms (USA)
Daniel Martinez
Lead Big Data Engineer (Streaming & Real-Time Systems)
New York, NY, USA | danielmartinez-data@mail.com | linkedin.com/in/danielmartinez-ny
Summary
Lead Big Data Engineer with 10+ years of experience building streaming infrastructures for media and entertainment platforms. Specialized in sources using Spark, Kafka, and Flink to deliver low-latency insights. Proven success in creating scalable ingestion pipelines from scratch, cleaning data for real-time dashboards, and ensuring efficient data processing at scale. Strong communication across teams, committed to delivering business intelligence with measurable impact.
Technical Skills
● Streaming: Kafka, Spark Streaming, Flink
● Cloud: AWS (Kinesis, EMR, Redshift), GCP Pub/Sub
● Databases: Cassandra, PostgreSQL, Oracle
● Tools: Docker, Kubernetes, Airflow, Git
● BI: Looker, Tableau
Experience
Lead Data Engineer | Netflix, New York | 2019–Present
● Designed streaming pipeline processing 200K+ events per second upon AWS Kinesis, delivering actionable insights with sub-second latency.
● Migrated legacy Oracle workloads to AWS EMR, reducing costs by $1.5M annually.
● Cleaned data pipelines to ensure 99.9% accuracy in recommendation systems; boosted personalization relevance by 17%.
● Interacted with developers and product managers to align streaming data flows with business requirements.
Senior Data Engineer | Spotify, New York | 2015–2019
● Built ingestion system from scratch with Kafka + Spark, reducing downtime incidents by 45%.
● Created BI dashboards in Looker, providing executives real-time views of listener statistics.
● Implemented automated monitoring and tuning of clusters, ensuring 99.95% uptime.
Education
B.Sc. Computer Engineering | Columbia University, New York | 2014
Certifications
Databricks Data Engineer Professional
● AWS Advanced Networking Specialty
Your Big Data Engineer resume is the essential foundation for getting noticed, but a stellar application requires more than just a list of skills. This video provides a step-by-step guide to crafting a compelling cover letter, which acts as your personal pitch to explain why your background is a perfect match for the role. Master this approach to ensure the impressive experience on your resume translates into a truly stand-out job application that gets more interviews.
How to Write a Winning Data Engineer Resume: Structure & Section Guide
What should you include in the best data engineer resume? There's no strict universal format – you can adapt the template to your experience and achievements. But two rules always apply:
1. Readability for hiring managers: They spend only 7–10 seconds reviewing candidate profiles, so key information – experience, skills, achievements – must be visible and easy to find.
2. Job requirements & ATS compliance: Before reaching human eyes, your resume gets scanned by software (ATS) that searches for relevant keywords and phrases.
In other words: your data engineer resume must work for both humans and machines. The safest bet is to stick to a structure that recruiters and ATS both recognize.
Universal Big Data Engineer Resume Template: Familiar to HR Managers & ATS-Friendly
Required Big Data Engineer Resume Sections
● Header — Name, contact info (phone, email), LinkedIn, GitHub, portfolio links.
● Summary / Professional Objectives — 2–5 sentences highlighting your level, core technologies, key achievements.
● Technical Skills — A categorized list of tools and technologies (Big Data, Cloud, Programming, Databases).
● Experience — Professional history with achievement-driven bullets (formula: Task → Action → Result). Include metrics where possible.
● Education — Degree(s), university, graduation year.
Optional Sections That Strengthen Your Application
● Certifications — AWS, GCP, Databricks, Cloudera, and more.
● Projects — Open-source contributions, personal, or hackathon projects.
● Publications & Conferences — Articles, talks, or presentations.
● Languages — Useful for international or multilingual roles.
● Soft Skills — For Big Data Engineer Resume crucial personal skills such us strong communication skills, problem solving, analytical thinking etc.
● Awards & Recognition — Professional awards, internal company honors.
Pro tip: For early-career Big Data engineers, optional sections (projects, certifications, courses) help compensate for limited work experience and demonstrate your commitment to the field.
Header with Contact Information: First Impressions Matter
Your resume header is the first thing recruiters and ATS see — make it clean, professional, and easy to read. This small section sets the tone for everything that follows, so getting it right means starting strong
What to include:
✔ Full name
✔ Job title, specialization (e.g., Big Data Engineer)
✔ Phone number (with country code if applying internationally)
✔ Professional email address (avoid casual handles)
✔ LinkedIn profile (essential for US, Canada, EU applications)
✔ GitHub or portfolio link (if you have relevant projects — this is where employers go to see your code in action)
✔Location (optional — include only if required in the job posting)
Seems simple, but some candidates make mistakes here that automatically hurt their chances. Even a small error in this section can leave a negative impression before anyone reads your qualifications.
Common resume header mistakes to avoid:
❌ Using creative fonts — these look unprofessional and are hard to read.
❌ Nicknames instead of your full name — can raise suspicions, seems unprofessional.
❌ Casual emails like kittycat@... or macho97@... — makes recruiters question your professionalism. Remember, everything on your resume speaks to who you are as a professional.
❌ Adding unnecessary personal info (marital status, number of children, full home address, Facebook or Instagram link) — irrelevant and outdated. Modern resume standards have moved beyond this.
How Big Data engineer resume contact section should look:
Nicholas Peterson
Big Data Engineer
+1 889 12 34 567 | nicpetersen.dataengineer@gmail.com | linkedin.com/in/nicpetersenDE | github.com/npetersondata
Pro Tip: For data engineers, a LinkedIn and GitHub/portfolio links aren’t just “nice-to-have” — they let employers instantly validate your skills, code quality, and professional network. This is particularly important in technical roles, where your online presence reflects your engagement with the broader tech community.
Professional Summary vs. Career Objective: Choosing Your Opening
Your opening section sets the tone. Choose the format based on your experience level. This decision might seem small, but it shapes how recruiters perceive your entire application right from the start.
Professional Summary (for experienced engineers)
A 3-4 line paragraph that immediately establishes your value. Think of it as your elevator pitch—capturing years of experience, core technologies, and standout achievements. This is your chance to introduce yourself in a manner that displays confidence without sounding arrogant.
Components of a strong resume summary:
✔ Years of relevant experience
✔ Key technologies & platforms
✔ Most impressive quantifiable achievement
✔ Alignment with target role
Why it matters: Recruiters spend seconds on the top of your resume. A tight summary tells them who you are and why you’re worth reading further. If done right, it puts you ahead of others competing for the same position.
Example comparison:
❌ Weak:
“Experienced engineer with knowledge of big data technologies. Worked with databases and ETL. Looking for opportunities to grow and apply my skills.”
Example is too generic and vague. No experience level, no specific technologies, no achievements or metrics. It could apply to anyone, which means it doesn't help you stand out. This is the wrong way to introduce yourself.
✅ Strong:
“Senior Big Data Engineer with 7+ years designing large-scale data pipelines on AWS and Spark. Expert in real-time streaming with Kafka and Flink, optimized workflows that reduced data processing time from 12h to 30 min. Proven track record building cloud-native platforms supporting 100M+ daily user events.”
The resume summary example immediately shows who the candidate is, experience level, mastered technologies, and most importantly – visible business results. Numbers and concrete achievements confirm experience and grab recruiter attention. This version clearly connects the dots between skills and outcomes.
Career Objective (For Entry-Level Engineer Resume)
A focused 2-3 sentence statement emphasizing your goals, relevant preparation, and enthusiasm. Perfect for recent graduates, career changers, or those with limited professional experience. This is your opportunity to express your vision for your career and demonstrate self-awareness about where you're going.
Strong resume objective components:
✔ Clear career direction
✔ Relevant skills & educational background
✔ Value proposition & learning mindset
✔ Alignment with company mission
Why it matters: When you lack extensive work history, your objective shows potential employers that you understand the role and bring transferable skills, academic achievements, or demonstrated passion for learning new tech.
Example comparison:
❌ Weak:
“Looking for a job as a Big Data Engineer where I can use my skills and grow in my career.”
This tells the reader nothing specific. What skills? Why this role? What value do you bring? It focuses on what you want rather than what you offer. This generic approach won't inspire confidence.
✅ Strong:
“Recent Computer Science graduate seeking to leverage hands-on experience building data pipelines with Spark, Kafka, and AWS through academic projects and internships. Eager to deepen expertise in distributed systems, quickly master new tools, and contribute to a company that values innovation and continuous growth. Passionate about transforming raw data into actionable insights that drive business decisions.”
This version reflects clarity of purpose and demonstrates that you've already begun your journey into Big Data engineering. It shows you know what the role entails and have taken steps to prepare yourself. The language flows naturally while hitting all the right points.
Bottom line: Weak openings use generic phrases that could apply to anyone. Strong openings combine specific skills, technologies, and measurable results to hook recruiters in seconds. The difference between the two might determine whether your resume receives a second glance or goes into the rejection pile.
Professional Skills Section Strategy
Your skills section is one of the first things recruiters and ATS will scan. The goal is to make it easy to read while proving you can actually apply those technologies. Narrow the list down to 10–15 most relevant skills for the role (senior engineers or team leads can include up to 20).
For Reverse-Chronological Resumes:
List skills as bullet points grouped by category. Skip descriptions—let your experience section show skills in action.
Example:
TECHNICAL SKILLS
- Big Data Frameworks: Apache Spark, Kafka, Airflow, Hadoop
- Cloud Platforms: AWS (S3, EMR, Redshift), GCP (BigQuery, Dataflow)
- Programming Languages: Python, Scala, SQL
- Databases: PostgreSQL, MongoDB
- DevOps & Infrastructure: Docker, Kubernetes, Terraform
- BI & Visualization: Tableau, Power BI, Looker
- Methodologies: Agile, Scrum
Critical insight: Don't just list tools—prove them. Reference these technologies throughout your experience and project sections with specific use cases and measurable results – proving not just technology familiarity, but ability to create company value.
For example:
● “Optimized Spark pipelines, cutting processing time from 6 hours to 45 minutes.”
● “Built Tableau dashboards that reduced reporting prep time by 30%.”
For Functional Resumes
A functional format emphasizes skills and achievements rather than work history. It’s a good fit if you:
● Have freelance projects, internships, or varied short-term experience;
● Want to highlight specific technical expertise;
● Have employment gaps but strong project-based results.
Since work history is condensed, your skills section becomes the centerpiece. Demonstrate competency through concrete achievements under each skill group.
How to structure it:
1. Choose 3–5 core skill groups (e.g., ETL pipelines, cloud infrastructure, containerization, data visualization).
2. List 1–2 main tools for each group.
3. Add 1–3 bullet points with use cases and outcomes.
To create strong bullets, use this formula: “What you did (technology/group) + Tool/Tech stack + Result.”
Example skills section for functional Big Data Engineer resume:
DATA PIPELINE ARCHITECTURE (Spark, Kafka, Airflow)
- Designed real-time streaming architecture processing 50 GB/hour from IoT sensors
- Implemented fault-tolerant pipelines with 99.9% uptime leveraging Kubernetes orchestration
- Reduced data latency from 5 minutes to under 30 seconds for critical dashboards
CLOUD INFRASTRUCTURE & COST OPTIMIZATION (AWS, Docker)
- Migrated on-premises ETL to AWS EMR, reducing infrastructure costs by 35%
- Containerized applications with Docker for consistent cross-environment deployment
- Automated CI/CD workflows, accelerating production releases by 50%
DATA QUALITY & ETL (Informatica, Talend)
- Built data validation framework improving accuracy by 25% across warehouse
- Consolidated 8 source systems into unified data model supporting analytics team
- Reduced manual data reconciliation time from 2 days to 4 hours monthly
Bottom line:
Whether chronological or functional resume, pair every tool with proof. Recruiters want evidence you can deliver results, not just recognize acronyms.
Professional Experience: Your Career Story
The structure and length of Work Experience section depend on your resume format.
✔ Functional resume: List previous roles and dates of employment only. The main focus shifts to skills and education, with the skills section carrying the most weight.
✔ Chronological resume: Experience is the centerpiece of your resume. Recruiters scan here immediately after summary and professional skills to evaluate your background.
What to Include in Your Work Experience Section
● Company name with employment dates
● Job title (add brief company description if not well-known)
● 3-5 achievement-focused bullet points per role
● Technologies used with business impact delivered
List previous positions in reverse chronological order — most recent first. If promoted within one company, show each role separately to demonstrate career progression.
Pro tip: If you’ve held one position for years without advancement, or worked mainly as a freelancer, consider a functional or hybrid resume. This helps highlight technical skills and results instead of static job titles.
Writing Impactful Experience Descriptions
Transform responsibilities into compelling achievements:
● Focus on business outcomes rather than daily tasks—show problems solved with value created
● Use strong action verbs: architected, optimized, implemented, reduced, improved, led, mentored
● Always back achievements with metrics: speed, cost, scale, or reliability
● Provide context: explain the challenge, your approach, and the measurable result
● Integrate keywords (Spark, Kafka, AWS, etc.) for ATS parsing and instant relevance.
Weak vs. Strong Examples
❌ “Worked with AWS systems”
✅ “Designed and deployed AWS pipelines, boosting processing speed by 30%.”
❌ “Maintained data pipelines”
✅ “Optimized ETL workflows, reducing runtime by 73% and improving reliability to 99.9%.”
❌ “Collaborated with team members”
✅ “Led cross-functional team integrating ML models into production, improving predictive accuracy by 25% and generating $2M additional revenue.”
❌ “Responsible for large data processing”
✅ “Architected scalable platform handling 100 TB+ daily, enhancing analytics and decision-making capabilities.”
❌ “Ensured data integrity”
✅ “Migrated 5 TB+ from on-prem to AWS Cloud with 99.9% accuracy and zero downtime.”
Bottom line: Recruiters want to see impact, not job descriptions. When writing the data engineer resume, every bullet should answer:
“What problem did you solve, how did you solve it, what technologies you used, and what measurable difference did it make?”
SAR & STAR Formulas for Writing Experience
Structure your achievements using proven formulas that provide context and demonstrate impact.
SAR (Situation-Action-Result)—Concise Impact
● Situation: The challenge or context
● Action: What you specifically did
● Result: The measurable outcome
Example:
“Built a Spark-based data pipeline (Action) for the marketing team facing 24-hour reporting delays (Situation), reducing report generation time to 30 minutes and enabling real-time campaign optimization (Result).”
STAR (Situation-Task-Action-Result)—Detailed Storytelling
This is a more detailed formula:
● Situation: The challenge or context
● Task: Your specific responsibility
● Action: Steps taken and technologies used
● Result: Quantifiable business impact
Resume example:
“E-commerce platform struggled with inventory forecasting accuracy during peak seasons (Situation). Tasked with designing ML-ready data pipeline for real-time demand prediction (Task). Implemented Lambda architecture using Spark Streaming, integrating 15 data sources including web analytics, inventory systems, and external market data (Action). Delivered pipeline supporting ML models that improved forecast accuracy by 35% and reduced inventory overstock costs by $1.2M annually (Result).”
When to use each:
● SAR for concise, results-driven bullets when space in resume is limited
● STAR when you want to showcase complex problem-solving and business context
Tip: Always use action verbs and numbers, include technologies used.
50+ Power Verbs for Data Engineer Resume
Writing Big Data Engineer resume, replace weak phrases like “responsible for” or “helped with” using impact-driven verbs:
Architecture & Development: Architected, designed, engineered, implemented, developed, built, created, deployed, integrated, refactored
Optimization & Performance: Optimized, accelerated, enhanced, streamlined, reduced, improved, scaled, tuned, automated, upgraded
Leadership & Collaboration: Led, directed, mentored, guided, coordinated, facilitated, drove, managed, influenced, trained
Analysis & Innovation: Analyzed, evaluated, identified, discovered, innovated, solved, transformed, modernized, pioneered, delivered
Results & Impact: Achieved, generated, increased, decreased, saved, delivered, exceeded, accelerated, eliminated, boosted
Education Section Strategy
For Mid-Level & Senior Engineers
Education plays a supporting role compared to professional experience. Recruiters usually just need confirmation of your academic background — keep it simple and factual.
What you should include to your resume:
● Degree type and field (Bachelor’s, Master’s, PhD)
● University name with graduation year
● Optional: honors, awards, or relevant achievements if they significantly strengthen your profile.
For Entry-Level & Recent Graduates
Education becomes a crucial section for demonstrating your foundation and practical skills.
Include:
● Degree type, field;
● University with graduation year
● GPA (if 3.5 or higher)
● Relevant coursework (e.g., Data Structures, Machine Learning, Distributed Systems, Cloud Computing)
● Thesis or capstone project titles if related to the role
● Academic projects with technologies used and outcomes
Pro Tip. When describing projects, coursework, or lab work, explain what tools you used and what results you achieved. Use strong action verbs and add measurable outcomes.
Big Data engineer resume example:
Bachelor of Science in Computer Science
University of Washington, Seattle — Graduated 2024
GPA: 3.7/4.0
Relevant Coursework: Machine Learning, Distributed Systems, Database Systems, Cloud Computing, Data Mining
Senior Capstone: “Real-Time Fraud Detection Pipeline Using Apache Kafka and Spark”
- Built streaming analytics platform processing 10,000+ transactions per minute
- Achieved 95% fraud detection accuracy with sub-100ms latency
- Deployed on AWS with Docker and CI/CD automation
Projects Section (Career Game-Changer)
If you're entry-level or transitioning into data engineering, a strong Projects section in your resume can level the playing field with more experienced candidates. It compensates for limited work experience and proves your ability to apply skills in practice.
What to Include
● Project type: Academic, personal, or open-source contribution
● Your role: Specific responsibilities and contributions
● Tech stack: Technologies and tools utilized
● Result: Measurable outcomes or value created
Tip: Write project bullets using the same achievement-driven style as your professional experience section.
Resume example:
Real-Time Social Media Analytics Platform
● Built end-to-end streaming pipeline using Kafka, Spark, and Elasticsearch
● Processed 100K+ tweets/hour for sentiment analysis and trend detection
● Deployed on AWS with Docker and auto-scaling
● Result: enabled brand monitoring with 30-second data freshness
Predictive Maintenance Data Lake
● Designed cloud-native architecture on GCP integrating IoT sensor data
● Implemented Delta Lake medallion architecture for data quality management
● Built ML feature store supporting 20+ predictive models
● Result: reduced equipment downtime by 25% with proactive maintenance scheduling
Certifications: Your Professional Credibility
Market analysis shows 60% of Big Data Engineer job postings explicitly mention certifications. For entry-level engineers, they compensate for limited experience. For experienced professionals, they validate expertise with modern technologies.
What to include:
● List certifications without additional descriptions
● Keep certifications current—most expire or lose value in 2–3 years
● Prioritize certifications matching the company's tech stack
Resume Example:
CERTIFICATIONS
- AWS Certified Data Analytics – Specialty (2024)
- Databricks Certified Data Engineer Professional (2023)
- Google Cloud Professional Data Engineer (2023)
Pro Tip: Quality over quantity—3 relevant certifications aligned with the job description beat 10 generic ones. If the role emphasizes AWS and Redshift, an AWS Specialty cert carries more weight than a GCP one.
Most Valuable Certifications for Big Data Engineers (2025)
Cloud-Focused:
● AWS Certified Data Analytics – Specialty
● Google Cloud Professional Data Engineer
● Microsoft Azure Data Engineer Associate
Platform-Specific:
● Databricks Certified Data Engineer Professional
● Snowflake SnowPro Core Certification
● Cloudera Data Platform Generalist
Strategy by Career Stage:
Junior Big Data Engineers: Focus on foundational cloud skills
● Google Cloud Professional Data Engineer
● AWS Solutions Architect Associate
● Azure Data Fundamentals
Mid-Level Big Data Engineers: Show specialized expertise
● AWS Data Analytics Specialty
● Databricks Data Engineer Associate
● Snowflake SnowPro Core
Senior Big Data Engineers: Demonstrate advanced capabilities
● Databricks Data Engineer Professional
● AWS Advanced Networking Specialty (for large-scale infrastructure)
● Google Cloud ML Engineer (if working with ML pipelines)
Tailoring Strategy for Big Data Engineer Resume by Experience Level
Your resume should reflect not only your technical skills but also your level of professional maturity. The career narrative shifts depending on where you are: for a junior engineer, it’s about potential and foundation; for mid-level, it’s about growth and measurable results; for senior, it’s about leadership and strategic impact.
Junior/Entry-Level Focus
At the start of your career, the focus is on demonstrating potential, willingness to learn, and a solid theoretical background.
Key resume sections: Education (including strong GPA), internships, academic projects, relevant certifications.
Language style: “Experience with,” “Knowledge of,” “Familiar with”—emphasizing tool familiarity and learning capability.
Resume Length: Strictly 1 page.
Emphasis: Show ability to apply classroom knowledge to practical problems through projects and internships.
Avoid: long lists of technologies without practical examples, irrelevant projects that don’t reflect interest in Big Data.
Mid-Level Strategy
For mid-level professionals, the main task is to show career progression and the ability to independently solve complex problems with measurable outcomes.
Key resume sections: Professional experience with quantified achievements, technical leadership examples, cross-functional collaboration.
Language style: “Implemented,” “Optimized,” “Developed,” “Led”—demonstrating ownership and results.
Resume Length: Typically 1 page (dense but well-organized).
Emphasis: Career progression, production environment experience, mentorship of junior team members.
Common mistake: describing responsibilities instead of achievements, failing to include quantifiable results (e.g., speed, scale, cost savings).
Senior/Lead Approach
At this level, your resume should tell a story of leadership, strategic thinking, and business impact.
Key resume sections: Professional experience emphasizing large-scale initiatives, team leadership, architectural decisions
Language style: “Architected,” “Directed,” “Transformed,” “Scaled”—indicating strategic influence
Resume Length: 1–2 pages for complex project portfolios
Emphasis: Business outcomes, technical strategy, team development, cross-organizational influence
Avoid: focusing on basic tasks or listing technologies without context; lack of emphasis on leadership weakens your profile.
A powerful Big Data Engineer resume gets your foot in the door, but knowing how to articulate your experience is what lands the job. The STAR method—Situation, Task, Action, Result—is the globally recognized formula for impressively detailing your professional accomplishments to recruiters. Use this video guide to master the technique, ensuring the impressive skills on your resume translate into compelling, clear interview stories.
Big Data Engineer Resume Templates Adapted for the Level of Experience
Junior Big Data Engineer Resume Example (Functional Format)
Alex Thompson
Big Data Engineer
Melbourne, Australia
+61 400 123 456 | alex.thompson@email.com | linkedin.com/in/alexthompson | github.com/alexthompson
Career Objective
Recent graduate with knowledge of Python, SQL. Experience with Hadoop, Spark through academic projects. Eager to land your data engineering roles.
Professional Skills
Programming Languages
- Python: Built ETL scripts for data processing.
- SQL: Optimized queries on different data sets.
Big Data Frameworks
- Apache Spark: Processed financial data in projects.
- Hadoop Ecosystem: Managed HDFS storage for modelling techniques.
- Apache Kafka: Handled real-time streams in simulations.
Cloud Platforms
- AWS: Deployed S3 buckets for data management.
Databases
- PostgreSQL: Designed schemas for data driven apps.
- MongoDB: Stored structured and unstructured data, data modeling.
Other Tools
- Docker: Containerized apps for reducing system downtime.
- Git: Versioned code in team settings.
- Tableau: Visualized insights from services and data.
Key Achievements & Projects
● Data Pipeline Project (Academic, University of Melbourne, 2024)
● Developed ETL pipeline using Spark. Processed 500 GB datasets. Reduced load time by 40%. Applied data modeling for business analyst needs.
● Financial Data Analysis Tool (Personal Project, 2025)
● Built Python app with SQL queries. Analyzed stock market data. Improved prediction accuracy by 25%. Used Google Docs for docs resume documentation.
● Real-Time Monitoring System (Internship Project, Commonwealth Bank, Melbourne, 2024)
● Implemented Kafka streams for performance data. Integrated with AWS services. Enabled quick review your metrics.
Work Experience
● Data Intern, Commonwealth Bank, Melbourne (June 2024–December 2024)
● Software Engineer Intern, Telstra, Sydney (January 2024–May 2024)
Education
Bachelor’s Degree in Computer Science
University of Melbourne, Australia, 2021-2024
GPA: 3.8/4.0
● Relevant Coursework: Data Structures, Machine Learning
Certifications
● AWS Certified Cloud Practitioner, 2025
● Google Data Analytics Certificate, 2024
Conferences
● Attended Big Data & Analytics Summit Canada (Virtual), Toronto, June 2025
Mid-Level Big Data Engineer Resume Example
Jordan Patel
Big Data Engineer
London, UK
+44 20 1234 5678 | jordan.patel@email.com | linkedin.com/in/jordanpatel | github.com/jordanpatel
Professional Summary
Mid-level Big Data Engineer with 10 years of experience in data engineering roles. Expert in Python, Spark for building scalable pipelines. Optimized data systems, reducing processing latency by 35%. Delivered data management solutions for financial data at global banks. Google Cloud Professional Data Engineer Certified.
Professional Skills
● Python, Java, Scala, SQL
● Apache Spark, Hadoop, Kafka, Airflow
● AWS, Azure, GCP
● PostgreSQL, MongoDB, Redshift, Snowflake
● Docker, Kubernetes, Git, Tableau
● Data Modeling, ETL Tools
Work Experience
Big Data Engineer, Barclays, London (2022 — Present)
● Architected data pipelines using Spark, Kafka. Processed 10 TB daily from multiple data sources.
● Improved performance of data queries by 50%.
● Collaborated with business analyst teams on data driven decisions. Integrated services and data for more interviews in compliance audits.
Data Engineer, HSBC, Manchester (2019–2022)
● Developed ETL processes with Airflow. Managed financial data warehouses on AWS.
● Reduced costs by 30% through modelling techniques. Supported project manager in engineering roles. Format your resume templates for team reviews.
● Software Engineer, Lloyds Banking Group, Edinburgh (2017–2019)
● Built Java apps for data ingestion. Optimized SQL databases. Handled range from structured to unstructured data.
Education
Master of Science in Computer Science
Imperial College London, UK, 2015-2017
Certifications
● AWS Certified Data Analytics — Specialty, 2024
● Google Cloud Professional Data Engineer, 2023
Projects
Fraud Detection Pipeline (Barclays Internal, 2023)
● Designed Spark-based system for real-time financial data. Detected anomalies with 95% accuracy.
Cloud Migration Initiative (HSBC, 2021)
● Led transfer to Azure Synapse. Streamlined data management for 500 users.
Conferences
Presented at Big Data & AI World, London, March 2025
Senior Data Engineer Resume Example
Taylor Ramirez
Senior Data Engineer Resume
San Francisco, CA, USA
(415) 123-4567 | taylor.ramirez@email.com | linkedin.com/in/taylorramirez | github.com/taylorramirez
Professional Summary
Senior Data Engineer with a decade of experience leading data engineering roles. Architected scalable platforms using Spark, Kafka at FAANG companies. Reduced processing costs by 45% through advanced data modeling. Delivered solutions for financial data, performance data across global teams. Excelled in reducing system failures.
Professional Skills
● Python, Java, Scala, SQL, R
● Apache Spark, Hadoop, Kafka, Airflow, Flink
● AWS, Azure, GCP
● PostgreSQL, MongoDB, Cassandra, Redshift, Snowflake
● Docker, Kubernetes, Git, Tableau, Power BI
● Data Management, Data Modeling, Modelling Techniques
Work Experience
Senior Data Engineer, Meta, Menlo Park (2021 — Present)
● Led team of 12 engineers in building data pipelines with Spark.
● Processed petabyte-scale datasets from different data sources.
● Optimized queries, reducing system latency by 60%.
● Collaborated with business analyst, project manager on data driven strategies. Integrated services and data for AI models.
Big Data Engineer, Amazon, Seattle (2017–2021)
● Architected AWS-based warehouses using Redshift.
● Managed financial data flows for e-commerce.
● Improved efficiency by 40% via modelling techniques.
● Led engineering teams in cloud migrations.
Software Engineer, Google, Mountain View (2014–2017)
● Designed and developed Java systems for data ingestion.
● Handled range from structured sources.
● Built ETL tools boosting performance data.
Education
Bachelor of Science in Computer Science
Stanford University, CA, USA, 2010-2014
Certifications
● AWS Certified Big Data — Specialty, 2024
● Databricks Certified Data Engineer Associate, 2023
● Google Cloud Professional Data Engineer, 2022
Projects
Global Analytics Platform (Meta, 2023)
● Designed Kafka-Flink system for real-time insights. Scaled to 1B daily events.
Cost Optimization Tool (Amazon, 2019)
● Created Python dashboard with Tableau. Cut infrastructure spend by $2M yearly.
Conferences
Spoke at IEEE BigData 2025, Macau, December 2025
Lead Big Data Engineer Resume Example
James Coleman
Principal Big Data Engineer
(925) 123-4567 | j.coleman.data@email.com | linkedin.com/in/jamescolemanbd | github.com/jcoleman-eng
Summary
Principal Big Data Engineer with 12+ years of experience architecting and managing robust, data-driven solutions for Fortune 500 clients. Proven mastery in designing scalable data services, leveraging various big-data algorithms and frameworks. Expert in setting security and privacy policy at the heart of data architecture, ensuring confidential data handling. A visionary leader poised to join a competitive organization and support its strategic goals.
Technical Skills
● Programming: Python, Java, Scala, SAS, Scripting
● Big Data Frameworks: Apache Spark, Hadoop (HDFS, MapReduce, Pig), Kafka, Flink
● Cloud & Infrastructure: AWS, Azure, GCP, Docker, Kubernetes, Linux/Unix
● Databases & Warehousing: Teradata, Snowflake, Datastax Cassandra, Parquet, Avro
● Other: Data Privacy & Security, API development, QA testing, Cybersecurity principles
Professional Experience
Principal Data Engineer | DataSolutions Inc., Austin, TX | 2019 – Present
● Led a team of 15 developers and data scientists, managing the complete lifecycle of data products.
● Architected a company-wide data service running on a cluster of 100+ instances, bringing together various data sources and improving data loading speed by 60%.
● Implemented a strict data access policy and security protocols, successfully passing client cybersecurity audits.
● Played a key role in hiring and mentoring staff, bringing in top talent and fostering a collaborative team environment.
Senior Big Data Engineer | Global Analytics Corp., Remote | 2015 – 2019
● Developed and optimized algorithms for real-time data processing, handling terabytes of data daily.
● Engineered solutions for data extraction, cleansing, and loading (ECL) using existing Hadoop ecosystem tools.
● Authored technical documentation and reports on findings, presenting to peers and directors.
● Took charge of troubleshooting complex issues involving data persistence layers.
Education & Certifications
● M.S. in Computer Science, Massachusetts Institute of Technology
● B.S. in Computer Engineering, University of Texas at Austin
● AWS Certified Solutions Architect – Professional
● Datastax Apache Cassandra Developer Certification
Visual Design & Formatting Best Practices
A professional resume balances visual appeal with readability. Good design enhances your content, helping recruiters find key information quickly. However, don't let creativity distract from substance — the goal is to create a polished document that's easy to scan while maintaining an outstanding first impression.
Design Principles
✔ Typography: Clean, readable fonts (Calibri, Arial, Helvetica) in 10-12pt. Avoid anything too stylized — your resume shouldn't require extra effort to read.
✔ White space: Maintain 1-inch margins and clear spacing between sections for easy scanning. This helps the reader's eyes flow naturally down the page without feeling overwhelmed.
✔ Consistency: Apply uniform formatting for headings, bullets, and body text throughout the entire document. Small inconsistencies in font size or bullet style can signal carelessness.
✔ Length: 1 page for entry-level; up to 2 pages for senior roles with extensive experience. If you're close to exceeding this limit, edit ruthlessly---every line should earn its place.
✔ Color: Minimal use; maintain high contrast for readability and ATS compatibility. A touch of color for section headers can work, but anything beyond that risks looking unprofessional or creating parsing issues.
✔ File naming: Use professional naming conventions like “FirstName-LastName-DataEngineer-Resume.pdf” when you're ready to download and send your document. This small detail speaks volumes about your attention to professional standards.
Final Technical Details for Crafting Stand Out Big Data Engineer Resume
✔ File format: Always save and send resume as PDF document with professional naming: “FirstName-LastName-DataEngineer-Resume.pdf”. This ensures your formatting remains intact regardless of how the reader opens it.
✔ ATS optimization: Use standard section headers, avoid tables/graphics that might confuse parsing algorithms, include keyword variations from job descriptions. Remember that before any human sees your resume, it might be filtered by software that uses specific rules to evaluate candidates.
✔ Proofreading: Check thoroughly for grammar, spelling, consistent verb tenses, accurate company names and dates, working contact information. Even a single typo can undermine your credibility and suggest you don't pay attention to details. Ask a colleague or member of your professional network to review it with fresh eyes — they might catch errors you've become blind to after multiple revisions.
✔ Version control: Keep a master version of your resume that you customize for each application. Store these in an organized manner so you can reference which version you sent to which company. This becomes important during interview preparation when you need to remember exactly what you emphasized.
✔ Regular updates: Don't wait until you're actively job searching to update your resume. Make it a routine practice to add new achievements, certifications, or projects as they happen. This ensures you won't forget important accomplishments later and makes the job search process much easier when the time comes.
Your Next Steps to Resume Success
Building a standout Big Data Engineer resume requires strategic thinking about your unique value proposition. You're not just showcasing technical skills — you're proving your ability to transform complex data challenges into business solutions. This is your opportunity to introduce yourself to potential employers and demonstrate why you're the right fit for their team.
Remember the core principles for strong Big Data Engineer resume:
● Lead with quantifiable business impact, not tool lists
● Tailor every application to specific job requirements and the latest industry trends
● Show progression and growth throughout your career story
● Balance technical depth with business context
● Let your passion for data engineering shine through authentic language
Your resume opens doors, but your skills and problem-solving ability will land the job. Invest the time to craft a compelling professional story that positions you as the data engineer companies need to succeed. Think of this document as the beginning of a conversation — one that could lead to exciting opportunities and career growth.
Whether you're just starting your journey or pursuing a senior leadership role, the ideas and strategies in this guide can help you create a resume that stands out. Remember that acing the interview starts with getting that first call, and a great resume is your ticket to making that happen.
Ready to build your winning resume? Take advantage of engineernow.org's professional resume builder designed specifically for engineers, get expert feedback with our resume analyzer, or accelerate your career growth with our comprehensive career development course “Engineer Millionaire”. Browse our collection of samples and guides to find inspiration for your own unique career path.
Don't let your dreams of working in Big Data remain just dreams. The tools and resources are available — it's up to you to take that first step. Your next breakthrough role starts with a resume that tells your story right, and today is the perfect day to begin.
Remember: in a competitive job market, your resume isn't just a formality — it's your most important marketing material. Treat it with the care and attention it deserves, and you'll be rewarded with interviews, offers, and ultimately, the career you've been working toward.
Frequently Asked Questions (FAQ) About Big Data Engineer Resumes
How can I make my resume stand out in a crowded job market?
Focus on quantifiable achievements, not just responsibilities. Use data-driven results to show impact. Incorporate keywords from the job description to pass ATS filters and show suitability. For security-focused roles, mention experience with data privacy policy implementation.
Which technical skills are 'must-have' versus 'nice-to-have'?
Mastery of core algorithms, distributed systems like Hadoop and Spark, and cloud services is essential. Knowing Parquet, Avro, and scripting (e.g., SAS, Pig) is highly valued. Familiarity with cybersecurity aspects and data privacy is increasingly important, especially in government or financial organizations.
How important are soft skills on a Big Data Engineer resume?
Very. Excellent interpersonal skills are crucial for collaborative environments. Mention experiences managing staff, bringing together cross-functional teams, or contributing to the community (e.g., a blog or GitHub). This conveys you're not just a technician but a team player.
Should I include certifications from Coursera?
Yes, especially if you are beginning your career or seeking to develop new proficiencies. List job-relevant programs from Coursera or other platforms to show ongoing learning and understanding of emerging technological blocks.

Written by
Recent Posts

Pub: 12 Oct 2025 - Upd: 01 May 2026
27 min. read
Structural Engineering Resume Examples: Complete Guide for 2026

Pub: 09 Sep 2025 - Upd: 01 May 2026
14 min. read
Engineering Internship Resume Examples: 5 Samples That Get Hired in 2026
Pub: 25 Feb 2026 - Upd: 01 May 2026
58 min. read
Cable Technician Resume Examples & Guide: From Job Posting to Job Offer in 30 Days